
Het programma voor de komende VOGIN-IP-lezing is nog niet klaar, maar er wordt wel hard aan gewerkt. Het vaste organiserende team is daartoe uitgebreid met een adviescommissie die vanuit verschillende achtergronden ideeën voor sprekers en workshops kan inbrengen en bespreken. Overleg vindt nog even via Zoom plaats. Maar ook dat blijkt heel inspirerend en vruchtbaar te kunnen zijn.
Het overleg heeft dan ook al geresulteerd in een flink aantal uitnodigingen aan potentiële sprekers en workshopdocenten. Voor de workshops zijn er zelfs al vijf toegezegd. Houdt hier onze berichten over de voortgang in de gaten.
Workshops
Vorige week bij VOGIN-IP, morgen bij De Taalstaat

Bij de VOGIN-IP-lezing vorige week verzorgde Ewoud Sanders tweemaal zijn populaire workshop “Slimmer zoeken in Delpher”. Deze week kwam het bericht dat hem de prestigieuze Groenman Taalprijs is toegekend. Morgen is Ewoud daarom te gast bij het programma De Taalstaat op Radio 1 (11:00 – 13:00 uur), waarin juryvoorzitter Hans Heestermans hem de prijs zal overhandigen.
Ewoud krijgt de prijs toegekend voor de taalrubriek WoordHoek waarvan hij tussen 2000 en 2020 in NRC meer dan duizend afleveringen verzorgde. Sinds vorig jaar wordt deze rubriek gecontinueerd op de website van het Instituut voor de Nederlandse taal. Met deze rubriek, waarin hij vooral op de herkomst van woorden en uitdrukkingen inging, wist hij volgens de jury van de Groenman Taalprijs de lezers van de rubriek „liefde voor en kennis van de Nederlandse taal” bij te brengen. Hoewel in zijn workshop bij ons de nadruk natuurlijk op slimmer zoeken lag, zal daarbij ook vast wel iets van die liefde voor de taal zijn overgebracht. Bovendien heeft zoeken sowieso een heel “talige” dimensie.

Foto’s: Eef Evers
Ewoud is met deze toekenning in goed gezelschap. Eerder werd de prijs onder meer al uitgereikt aan Paul Witteman, Frits Spits, Kees van Kooten, Adriaan van Dis en Tom Lanoye.
Als VOGIN-IP-team feliciteren we Ewoud van harte met deze prijs.
Waarom je naar de workshop van Erik Elgersma moet komen
Arno Reuser probeert je in drie minuten te overtuigen waarom de workshop van Erik Elgersma over de startende éénpitter in informatieland zo nuttig en interessant en zo leerzaam is. En waarom je daar 21 oktober dus beslist heen moet – ook als je zelf geen éénpitter bent trouwens.
Factchecked
Alexander Pleijter retweette gisteravond dit draadje (of zeg maar gerust “draad”) van een Vlaamse collega-factchecker, vergezeld van een zeer waarderend`commentaar. Inderdaad de moeite waard om die hele draad door te nemen. Daarin probeert Brecht Castel, naar aanleiding van een viraal antifaxers Facebook-bericht, antwoord te vinden op drie vragen: 1) Waar werd de foto genomen? 2) Wat is de context van de foto? En 3) Wie is deze vrouw en klopt haar boodschap?.
Maar daar hoef je het niet bij te laten als je beter toegerust wilt kunnen factchecken. Want Alexander Pleijter zelf verzorgt 21 oktober een twee uur durende workshop Zo word je factchecker waar nog veel meer algemene aanpak en tips en trucks aan de orde komen. Wel snel aanmelden, want het aantal plaatsen is beperkt.
Workshops in the making
Er komen al weer diverse interessante workshops aan voor het programma van 21 oktober, Vijf workshops zijn al definitief toegezegd en een paar zitten in de pijplijn.
 In ons online programma vorig jaar was er veel belangstelling voor de workshop “Maak je eigen Infographic” van Joyce van Aalten. In de live situatie op 21 oktober zal ze een verdere verdieping op dat thema verzorgen.
In ons online programma vorig jaar was er veel belangstelling voor de workshop “Maak je eigen Infographic” van Joyce van Aalten. In de live situatie op 21 oktober zal ze een verdere verdieping op dat thema verzorgen.
 Een heel nieuwe workshop in ons programma wordt gegeven door Erik Elgersma. In 2015 gaf hij al eens een zeer goed beoordeelde lezing over praktijkervaringen met de informatievoorziening bij Friesland-Campina. Nu zal hij je wegwijs maken hoe je als eenpitter een eigen informatiedienstverlening opzet.
Een heel nieuwe workshop in ons programma wordt gegeven door Erik Elgersma. In 2015 gaf hij al eens een zeer goed beoordeelde lezing over praktijkervaringen met de informatievoorziening bij Friesland-Campina. Nu zal hij je wegwijs maken hoe je als eenpitter een eigen informatiedienstverlening opzet.
 De workshop van Egon Willighagen stond vorig jaar wel al op ons voorlopige programma, maar kon toen helaas niet gegeven worden. Je leert daarin te werken met twee interesssante projecten die de bruikbaarheid en toegankelijkheid van Wikidata sterk verbeteren: WikiCite en Scholia.
De workshop van Egon Willighagen stond vorig jaar wel al op ons voorlopige programma, maar kon toen helaas niet gegeven worden. Je leert daarin te werken met twee interesssante projecten die de bruikbaarheid en toegankelijkheid van Wikidata sterk verbeteren: WikiCite en Scholia.
 Met alle nepnieuws dat rondwaart blijft factchecking een hot topic in ons vak. Op veler verzoek zal Alexander Pleijter, één van de drijvende krachten achter de site “Nieuwscheckers“, dan ook opnieuw een workshop geven hoe je een (goede) factchecker wordt.
Met alle nepnieuws dat rondwaart blijft factchecking een hot topic in ons vak. Op veler verzoek zal Alexander Pleijter, één van de drijvende krachten achter de site “Nieuwscheckers“, dan ook opnieuw een workshop geven hoe je een (goede) factchecker wordt.
 Een workshop “Slimmer zoeken in Delpher” werd al eens eerder gegeven, maar blijft de moeite waard nu in Delpher steeds meer gedigitaliseerde informatie beschikbaar is en de zoekmogelijkheden ook weer verbeterd zijn. Enig voorbehoud is op dit moment nog even dat niet definitief zeker is dat Ewoud Sanders op 21 oktober in het land zal zijn om die workshop te geven.
Een workshop “Slimmer zoeken in Delpher” werd al eens eerder gegeven, maar blijft de moeite waard nu in Delpher steeds meer gedigitaliseerde informatie beschikbaar is en de zoekmogelijkheden ook weer verbeterd zijn. Enig voorbehoud is op dit moment nog even dat niet definitief zeker is dat Ewoud Sanders op 21 oktober in het land zal zijn om die workshop te geven.
 De workshop “Hoe kom ik nu aan de full-text?” is ook al eerder gegeven. Maar aangezien enerzijds steeds meer publicaties open access beschikbaar komen en nieuwe tools die vindbaar proberen te maken, en anderzijds de uitgevers blijven proberen hun betaalmuren ondoordringbaarder te maken, is een update zeker de moeite waard. Uiteraard zal die weer worden verzorgd door Guus van de Brekel, in samenwerking met Robin Ottjes.
De workshop “Hoe kom ik nu aan de full-text?” is ook al eerder gegeven. Maar aangezien enerzijds steeds meer publicaties open access beschikbaar komen en nieuwe tools die vindbaar proberen te maken, en anderzijds de uitgevers blijven proberen hun betaalmuren ondoordringbaarder te maken, is een update zeker de moeite waard. Uiteraard zal die weer worden verzorgd door Guus van de Brekel, in samenwerking met Robin Ottjes.
Frank Huysmans zal de vorig jaar al aangekondigde workshop “Analyse van open data met open source software” verzorgen.



Bianca Kramer en Jeroen Bosman hebben in elk geval al toegezegd een workshop te verzorgen, maar beraden zich nog op een ander onderwerp dan dat wat ze afgelopen jaar al online verzorgd hebben.
Maar er zit nog meer in de pijplijn. Tegen de tijd dat de aanmelding voor de VOGIN-IP-lezing geopend wordt, zal er dus vast nog meer keuze zijn.
VOGIN-IP gaat weer online

We kondigden het al eerder aan, dat na het succes van het online voorjaarsprogramma ook weer aan een najaarsprogramma gewerkt werd. Intussen is dat programma al voor een groot deel gerealiseerd.
 Om te beginnen is er, in samenwerking met LexisNexis een workshop waarin je, aan de hand van hun zoekspecialist Marlies Segers, beter leert zoeken in het nieuws dat LexisNexis online aanbiedt. De (Nederlandse) verkiezingen van komend voorjaar worden daarbij als leidende casus gebruikt. Die workshop is al op 22 september, zodat het zaak is je snel aan te melden.
Om te beginnen is er, in samenwerking met LexisNexis een workshop waarin je, aan de hand van hun zoekspecialist Marlies Segers, beter leert zoeken in het nieuws dat LexisNexis online aanbiedt. De (Nederlandse) verkiezingen van komend voorjaar worden daarbij als leidende casus gebruikt. Die workshop is al op 22 september, zodat het zaak is je snel aan te melden.
Ook is intussen een tweetal lezingen gepland. Anders dan bij de workshops, is daarbij geen limiet gesteld aan het maximum aantal deelnemers.
 Op 25 september komt Laura Hollink van het Centrum voor Wiskunde en Informatica aan het woord. Zij houdt zich bij het CWI onder andere bezig met diverse aspecten van mens-machine interactie. Op basis van inzichten uit de cognitieve psychologie kijkt zij hoe knowledge graphs een rol kunnen spelen bij het verbeteren van de mens-machine interactie. Dit gezichtspunt is bij VOGIN-IP nog niet eerder aan de orde geweest.
Op 25 september komt Laura Hollink van het Centrum voor Wiskunde en Informatica aan het woord. Zij houdt zich bij het CWI onder andere bezig met diverse aspecten van mens-machine interactie. Op basis van inzichten uit de cognitieve psychologie kijkt zij hoe knowledge graphs een rol kunnen spelen bij het verbeteren van de mens-machine interactie. Dit gezichtspunt is bij VOGIN-IP nog niet eerder aan de orde geweest.
 Op 8 oktober is het virtuele podium voor Bianca Kramer. Zij zal een overzicht geven van huidige initiatieven op het gebied van twee soorten metadata: open citaties en open abstracts. De open infrastructuur waarvan die deel uitmaken dient transparant, toegankelijk en vrij van commerciële invloed te zijn. In een interactieve discussie zal Bianca een aantal voorbeelden verkennen van hoe deze metadata in de praktijk gebruikt kunnen worden, en welke voorwaarden daarvoor gelden.
Op 8 oktober is het virtuele podium voor Bianca Kramer. Zij zal een overzicht geven van huidige initiatieven op het gebied van twee soorten metadata: open citaties en open abstracts. De open infrastructuur waarvan die deel uitmaken dient transparant, toegankelijk en vrij van commerciële invloed te zijn. In een interactieve discussie zal Bianca een aantal voorbeelden verkennen van hoe deze metadata in de praktijk gebruikt kunnen worden, en welke voorwaarden daarvoor gelden.
 En last but not least in deze opsomming – en op de kalender al eerder dan de lezing van Bianca – is er een workshop van Arno Reuser. Daarmee komen we tegemoet aan een in eerdere evaluaties vaak uitgesproken wens. Hij zal op de hem eigen wijze ingaan op de basisprincipes van goed gestructureerd zoeken, waarvoor Booleaanse methoden nog altijd de grondslag vormen. Wel basisprincipes, maar zeker geen basale workshop. Op 30 september is Arno daarmee aan de beurt.
En last but not least in deze opsomming – en op de kalender al eerder dan de lezing van Bianca – is er een workshop van Arno Reuser. Daarmee komen we tegemoet aan een in eerdere evaluaties vaak uitgesproken wens. Hij zal op de hem eigen wijze ingaan op de basisprincipes van goed gestructureerd zoeken, waarvoor Booleaanse methoden nog altijd de grondslag vormen. Wel basisprincipes, maar zeker geen basale workshop. Op 30 september is Arno daarmee aan de beurt.
![]() Kijk vooral ook nog op de programmapagina. Daar vind je nog wat meer inhoudelijke details en kun je je voor elk van deze sessies aanmelden. De LexisNexis workshop zal via hun eigen webinar-tool gegeven worden. Voor de overige sessies wordt Zoom gebruikt.
Kijk vooral ook nog op de programmapagina. Daar vind je nog wat meer inhoudelijke details en kun je je voor elk van deze sessies aanmelden. De LexisNexis workshop zal via hun eigen webinar-tool gegeven worden. Voor de overige sessies wordt Zoom gebruikt.
Houd onze programmapagina ook verder regelmatig in de gaten, om te zien welke interessante aanvullingen er wellicht nog komen. Er zit nog wat in de pijplijn.
In memoriam Hugo Benne

Met de dood van Wouter Gerritsma nog altijd vers in ons geheugen, zijn VOGIN en de VOGIN-IP-lezing opnieuw getroffen door een afschuwelijk verlies. Voor ons allen totaal onverwacht, is 19 april Hugo Benne overleden. Naast zijn werk voor de Haagse Hogeschool, was Hugo ook docent bij de VOGIN-cursus en verzorgde hij bij de VOGIN-IP-lezing de laatste paar jaar diverse workshops met een meestal technische insteek.
Het echte verlies is er natuurlijk vooral voor zijn partner Heleen, voor zijn kinderen en voor verdere familie en kennissen. Hen wensen we heel veel sterkte om dit verlies te verwerken.
Wij gedenken Hugo met bovenstaande foto’s waarop we Hugo in actie zien tijdens VOGIN-IP-workshops in 2018 en 2019.
6 x P of “wat het Coronavirus met ons vak te maken heeft”
Door Jeroen Bosman en Bianca Kramer

Het genoom van het 2019-nCoV (Corona) virus
Dagelijks staan we versteld van de ingrijpende lokale en wereldwijde gevolgen van een nieuw virus. Virologische en epidemiologische vragen hebben snel een antwoord nodig, maar ook logistieke, economische en politiek-culturele kwesties rond het Coronavirus zijn dringend. Een half jaar wachten op antwoorden en inzichten kan niet. Elke dag scheelt. Bij crises rond sprinkhanenplagen of bosbranden is de behoefte aan snelle inzichten niet veel minder nijpend. Zelfs iets relatief traags als klimaatverandering en de effecten daarvan vraagt om inzichten op een termijn van maanden, niet van jaren. Ook zijn het allemaal complexe vraagstukken met veel verbanden en wereldwijde samenhangen die vragen om analyse van veel data en om samenwerking daarbij. De samenleving vraagt om meer en sneller onderzoek, waarbij de complexiteit en grootschaligheid dwingt tot samenwerking.
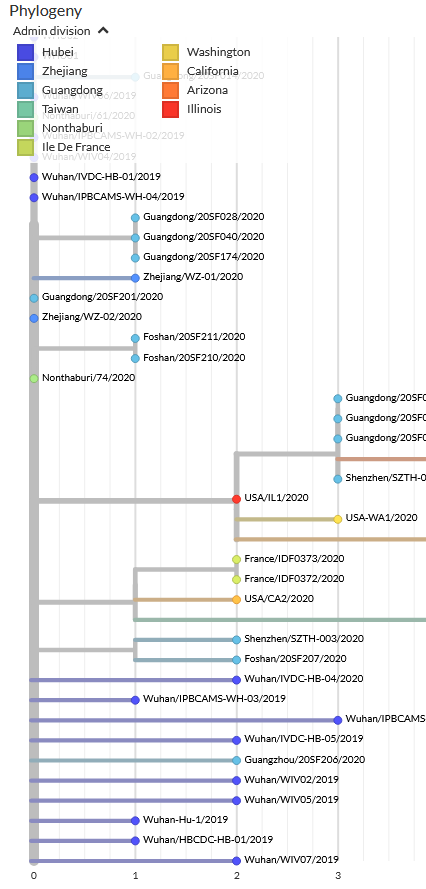
Corona philogenetic spread
Snel, vroeg en open
In dit soort omstandigheden kijken onderzoekers naar mogelijkheden om meer onderzoek te doen, en de uitkomsten daarvan in een eerder stadium te delen. Precies dat hebben we de afgelopen weken gezien: data van het genoom [boven] en van de verspreiding [rechts] worden online gezet.
Scripts om die data te analyseren worden gedeeld, vroege versies van papers (preprints) [onder] worden publiek gemaakt nog voor ze worden ingestuurd naar een wetenschappelijk tijdschrift. En dat alles openlijk, zodat anderen feedback kunnen geven of kunnen voortbouwen op (voorlopige) resultaten.
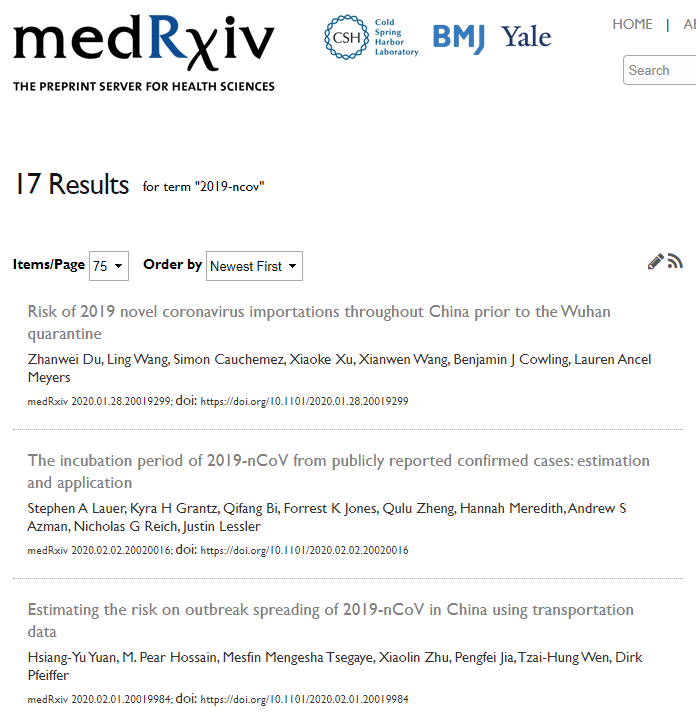
Coronavirus preprints in MedArXiv
Overigens gebeurt dit al een aantal jaren en niet alleen bij crises als nu rond Corona of eerder bij Ebola en Zika. Voor vrijwel al het onderzoek zijn er duidelijke voordelen van vroeg en open delen, zowel voor de onderzoeker zelf (vroege feedback, foutdetectie) als voor collega-onderzoekers (vermijden dubbel werk, gebruik van laatste data en inzichten) en de samenleving (toegang tot de meest actuele inzichten).
Zoeken, status en toepassingen
Op vele tientallen websites en platforms wordt de ‘vroege wetenschap’ gedeeld en tientallen zoekmachines helpen dat te vinden. Het gaat om, in volgorde van “verschijnen”: subsidieaanvragen voor onderzoek, projectomschrijvingen, data, code, posters, presentaties en preprints. Voor een deel zijn dat zaken waarvoor gespecialiseerde platforms zijn, voor een deel staat het in universitaire repositories of bij uitgevers. Jeroen Bosman heeft onlangs een start gemaakt om uit te zoeken welke platforms en zoekmachines dit soort materiaal vindbaar maken. Een verkleind beeld van de samenvatting daarvan zie je hieronder, met hier een link naar een grotere weergave en ook een link naar de beginpagina van de echte spreadsheet.
Zoekmachines voor vroege output – een spreadsheet
Vinden is echter niet de enige vraag rond dit soort vroege wetenschap. We moeten ook nadenken over de status van het materiaal. Waar is het voor bedoeld, wat voor checks heeft het ondergaan, wat voor rol speelt het in wetenschappelijke communicatie, en wat kunnen ‘derden’ ermee?
Alles met een P
In de workshop “Verkennen van de research frontier” gaan we naar al deze vormen van vroege wetenschap zoeken, kijken hoe simpel of gemakkelijk dat gaat en uitzoeken wat we met het materiaal kunnen doen. Heel toevallig gaat het (in het Engels) om allemaal documenttypen die met een P beginnen; 6 x P dus:
- Profielen die aangeven op welk terrein een onderzoeker actief is
- Proposals die aangeven aan wat voor onderzoek men wil gaan werken en waarvoor men dus financiering zoekt
- Projecten die beschrijven waaraan men nu werkt
- Posters die vroege uitkomsten tonen
- Presentaties die vroege uitkomsten bespreken
- Preprints, de vroege versies van papers
We durven te garanderen dat vrijwel iedereen een of twee, misschien zelfs drie of vier interessante nieuwe zoekmachines en tools zal leren kennen, waarmee de steeds belangrijker wordende vroege wetenschap gevonden kan worden.
Lens anyone? Base? Core? OpenAire? OSF? Share?
Virus scan
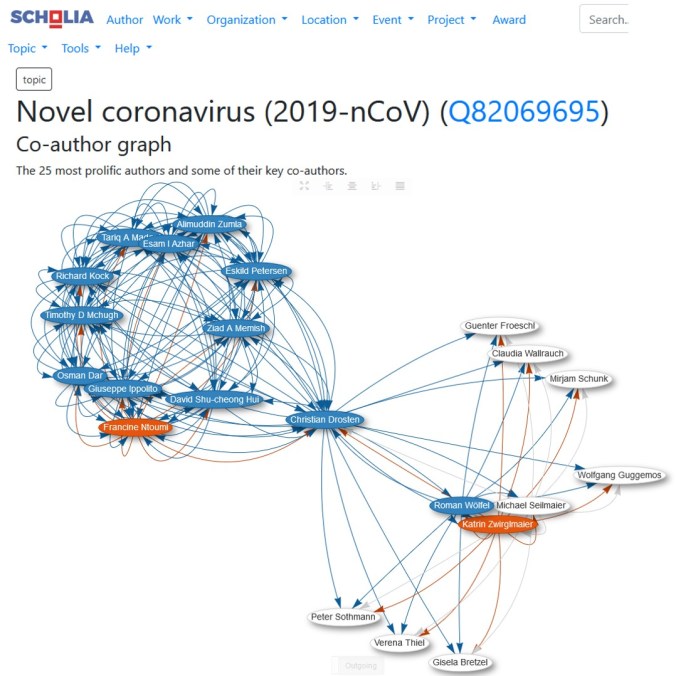
Als eye-catcher stond boven onze vorige blogpost een weergave van de relaties tussen auteurs/publicaties over het nieuwe Corona-virus, zoals dat met de Scholia-applicatie uit Wikidata-gegevens gegenereerd was. Nog maar vijf dagen later zag het beeld van dit hot topic er al weer heel anders uit, zoals je hierboven ziet. Wie wil weten hoe deze crisis zich verder ontwikkelt, voorzover dat zijn weerslag vindt in de wetenschappelijke literatuur, hoeft nu alleen maar op dit plaatje te klikken. Dat activeert de link voor een verse Scholia-actie voor dit onderwerp. Daarvoor hoef je dus niet eens deel te nemen aan de workshop van Egon Willighagen. Al is het natuurlijk veel leuker om dat wel te doen, want dan zul je zien dat er met Wikidata, Wikicite en Scholia nog veel meer kan dan deze “virus-scan”. </einde STER-spot>
Wikicite en Scholia
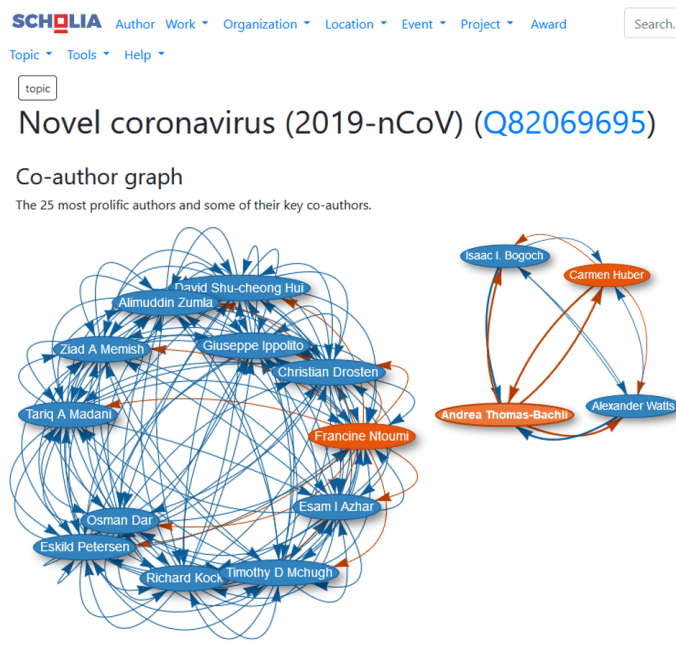
Bij de ruim 70 miljoen items die in Wikidata zitten, is een grote verscheidenheid aan soorten entiteiten. Dat loopt van vogelsoorten tot voetbalclubs, van wetenschappers tot woestijnen, van virussen tot violisten en van schilderijen tot scheikundige verbindingen.
 Waarvan er intussen ook al veel inzit, zijn wetenschappelijke publicaties. Niet die publicaties zelf, maar gegevens daarover. Een soort alternatieve catalogus dus, waarin de publicaties gelinkt zijn aan allerlei gegevens en eigenschappen. Daarbij natuurlijk auteurs en onderwerpen, maar ook citatiegegevens. Naar welke andere publicaties wordt in een artikel verwezen? Voor dat laatste is zelfs een speciaal project “WikiCite” opgezet, wat tot een soort gratis citatie-index kan leiden.
Waarvan er intussen ook al veel inzit, zijn wetenschappelijke publicaties. Niet die publicaties zelf, maar gegevens daarover. Een soort alternatieve catalogus dus, waarin de publicaties gelinkt zijn aan allerlei gegevens en eigenschappen. Daarbij natuurlijk auteurs en onderwerpen, maar ook citatiegegevens. Naar welke andere publicaties wordt in een artikel verwezen? Voor dat laatste is zelfs een speciaal project “WikiCite” opgezet, wat tot een soort gratis citatie-index kan leiden.
 Gespecialiseerde vrijwilligers uit de Wikimedia-gemeenschap voeren niet alleen – meestal geautomatiseerd – nieuwe gegevens in, maar ze bedenken ook zelf welke gegevens en welke relaties zinvol zijn om te registreren. Daarnaast ontwikkelen ze ook leuke tools om gegevens te zoeken, te analyseren en te visualiseren. Zo is er een tool Scholia, waarmee plaatjes gegenereerd kunnen worden van relaties tussen auteurs, van relaties tussen onderwerpen, van statistiek van tijdschriften, van statistiek van onderwerpen, van geografische verspreidingen en van nog veel meer.
Gespecialiseerde vrijwilligers uit de Wikimedia-gemeenschap voeren niet alleen – meestal geautomatiseerd – nieuwe gegevens in, maar ze bedenken ook zelf welke gegevens en welke relaties zinvol zijn om te registreren. Daarnaast ontwikkelen ze ook leuke tools om gegevens te zoeken, te analyseren en te visualiseren. Zo is er een tool Scholia, waarmee plaatjes gegenereerd kunnen worden van relaties tussen auteurs, van relaties tussen onderwerpen, van statistiek van tijdschriften, van statistiek van onderwerpen, van geografische verspreidingen en van nog veel meer.
Maar: het gaat zeker niet alleen maar om mooie plaatjes. Scholia is vooral ook een nuttig hulpmiddel om betrouwbare informatie en publicaties via Wikidata op het spoor te komen. En, anders dan bij klassieke databases en zoeksystemen, kun je zo zelf ook ontbrekende informatie en publicaties toevoegen.
 in het VOGIN-IP-programma is een workshop over WikiCite en Scholia opgenomen. Egon Willighagen, onderzoeker aan de Universiteit Maastricht en fervent Wikidata-enthousiast, zal de deelnemers wegwijs maken in de mogelijkheden en zal ze laten ontdekken hoe een en ander werkt. Om je vast enthousiast te maken, zie je in deze blogpost al wat visuele voorbeelden die met Scholia gegenereerd zijn.
in het VOGIN-IP-programma is een workshop over WikiCite en Scholia opgenomen. Egon Willighagen, onderzoeker aan de Universiteit Maastricht en fervent Wikidata-enthousiast, zal de deelnemers wegwijs maken in de mogelijkheden en zal ze laten ontdekken hoe een en ander werkt. Om je vast enthousiast te maken, zie je in deze blogpost al wat visuele voorbeelden die met Scholia gegenereerd zijn.

