
Onze 2023 keynote-spreker Elisabeth Bik was ineens weer in het nieuws. De Einstein Stiftung Berlin blijkt haar op 18 november de [nu voluit:] “Einstein Foundation Individual Award 2024” te hebben toegekend.
De Universiteit Utrecht, waar Elisabeth Bik haar opleiding kreeg en haar promotieonderzoek deed, sprong ook meteen trots bovenop dit bericht. En als organisatoren van de VOGIN-IP-lezing, die haar in 2023 voor een keynote-lezing hadden uitgenodigd, kunnen we daar natuurlijk niet bij achterblijven. Wij feliciteren Elisabeth van harte met deze mooie bekroning van haar onvermoeibare speurwerk naar gesjoemel in wetenschappelijke publicaties. Wat al eerder daarover op de VOGIN- en VOGIN-IP-sites verscheen:
- In de VOGIN Statafel podcast voerden hosts Bart van der Meij en Leon Heuts drie kwartier lang een inspirerend gesprek met Elisabeth Bik over haar talent om wetenschappelijke fraude op te sporen, over het belang van zuiverheid in de wetenschap en over de perverse prikkels in het wetenschappelijke bedrijf. Met tips & trucs waar je zelf op kunt letten als je een wetenschappelijke publicatie leest.
- De presentatie bij Elisabeth’s keynote
- Een interview met Elisabeth in vakblad IP, naar aanleiding van haar lezing.
Tot slot nog een paar feiten waar de Utrechtse DUB-site de nadruk op legde:
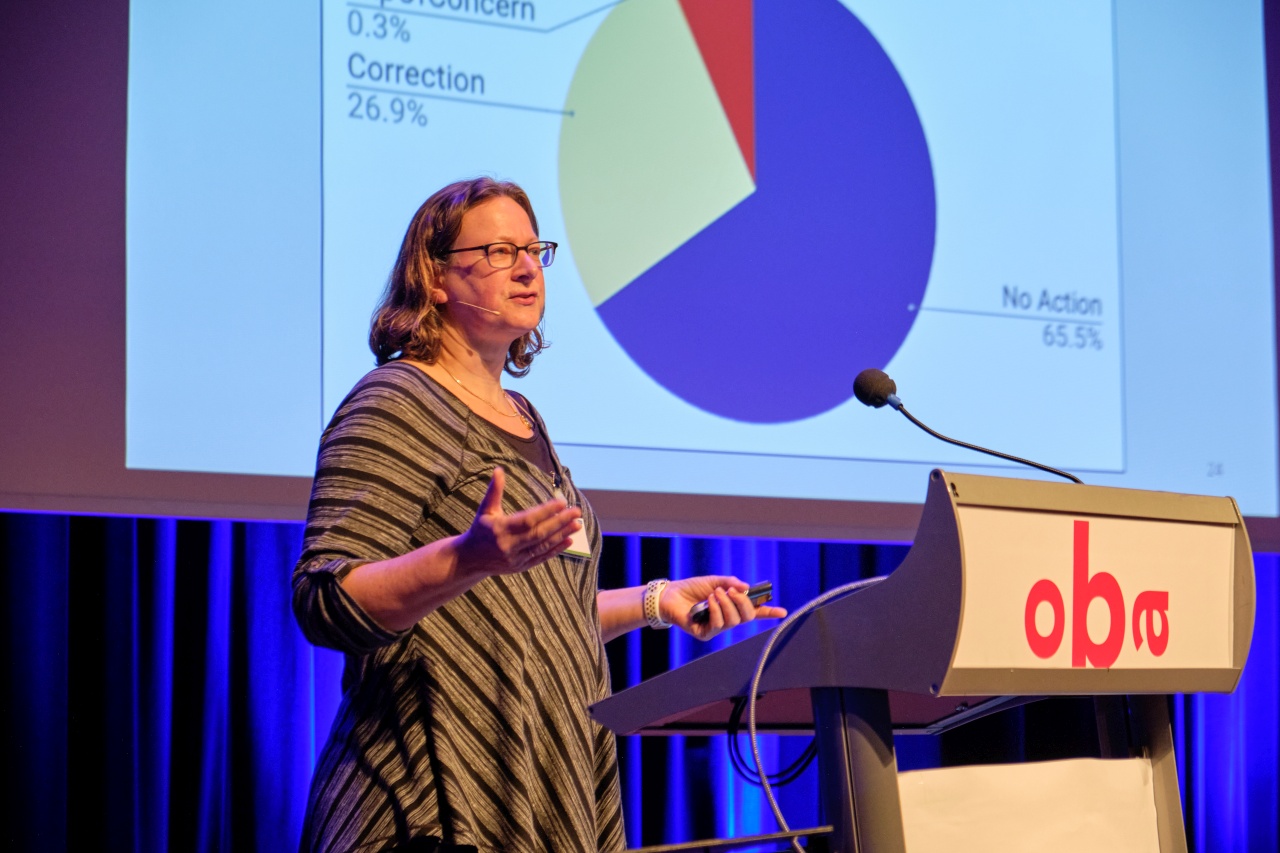
Bik heeft vooral een goed oog voor geknoei met beeldmateriaal. Ze ontdekte talloze beeldbewerkingen waarmee onderzoekers hun resultaten probeerden op te poetsen. Volgens de Einstein Foundation heeft ze fouten opgemerkt in 7.600 publicaties, waarvan er 1.100 zijn teruggetrokken.
Volgens de Einstein Foundation heeft Bik “wereldwijd enorme impact gehad” door fraude en manipulatie in de wetenschap bloot te leggen. Bik wil de 200.000 euro [van de prijs] gebruiken om haar fraudejacht voort te zetten.

 In 1999 peperde hij zijn toehoorders bij IP al in, dat het Booleaanse model voor de meeste zoektoepassingen volstrekt ongeschikt was. Nu, 25 jaar later, zijn de meeste mensen daar intussen wel van overtuigd – ook al zijn er nog altijd toepassingen waarvoor Booleaanse combinaties wel degelijk nog tot goede resultaten leiden.
In 1999 peperde hij zijn toehoorders bij IP al in, dat het Booleaanse model voor de meeste zoektoepassingen volstrekt ongeschikt was. Nu, 25 jaar later, zijn de meeste mensen daar intussen wel van overtuigd – ook al zijn er nog altijd toepassingen waarvoor Booleaanse combinaties wel degelijk nog tot goede resultaten leiden.












