
De workshop van Henk van Ess was als eerste al heel snel volgeboekt – en veel andere workshops volgden al gauw. Maar Henk verzorgt ook nog een lezing in ons middagprogramma. En die is zeker niet minder interessant. Daarvoor zijn in de grote zaal natuurlijk nog genoeg plaatsen beschikbaar. Vergeet dus niet om je voor dat lezingentrack aan te melden.
Je kunt dan ook meteen nog genieten van het vraaggesprek met Volkskrant-journalist Huib Modderkolk. De laatste tijd is die ook frequent op televisie te volgen. Maar daar kun je zelf geen vragen stellen en bij ons wel. En in dat zelfde lezingentrack zit dan ook nog Ellen Mok, met nog meer actuele politiek interessante beschouwingen. Genoeg aanleidingen dus om je voor dat lezingentrack te willen aanmelden
Lezingen
Prompten zonder zelf te hoeven prompten
 Vorige week was Henk van Ess een van de sprekers op VOGIN’s “omgevingscongres”. Daar liet hij zien hoe je met AI AI kunt genereren – onder meer hoe je kunt “prompten” zonder zelf te hoeven prompten. Hij liet al weten dat hij op 9 april bij de VOGIN-IP-lezing aanwezig zal zijn om dat ook te laten zien.
Vorige week was Henk van Ess een van de sprekers op VOGIN’s “omgevingscongres”. Daar liet hij zien hoe je met AI AI kunt genereren – onder meer hoe je kunt “prompten” zonder zelf te hoeven prompten. Hij liet al weten dat hij op 9 april bij de VOGIN-IP-lezing aanwezig zal zijn om dat ook te laten zien.
Zijn workshop in het ochtendprogramma is daar al volgeboekt. Maar in het middag-programma verzorgt hij ook een lezing in de theaterzaal. En daar is nog volop ruimte. Laat zijn verhaal je dus niet ontgaan en meld je aan.
Op jacht naar trollen en desinformatie
Interview met Robert van der Noordaa

Trollenlegers verspreiden op grote schaal desinformatie, en zeker in de laatste jaren is de hoeveelheid exponentieel gestegen. Met zijn bedrijf Trollrensics spoort Robert van der Noordaa deze netwerken op voor overheden en organisaties als de NAVO, zoals hij zal vertellen tijdens de aanstaande VOGIN-IP-lezing. Ondanks het succes voelt hij zich ook nog af en toe een roepende in de woestijn.
[Lees verder in de PDF van dit artikel uit IP|vakblad voor informatieprofessionals, 2025/2]
Europa als beschermer van de digitale democratie
IP in gesprek met hoogleraar José van Dijck

Al sinds het begin van haar carrière ziet José van Dijck de technologische ontwikkelingen elkaar in rap tempo opvolgen. In haar VOGIN-IP keynotelezing pleit de universiteitshoogleraar voor een sterke positie van Europa te midden van grootmachten Amerika en China, door op stevige regulering in te zetten en zuivere alternatieven te ontwikkelen.
[Lees verder in de PDF van dit artikel uit IP|vakblad voor informatieprofessionals, 2025/2]
Workshop of lezing?

De workshops beginnen al aardig vol te lopen. Van twee van de drie workshops die wegens succes 2x gegeven worden, is de tweede sessie ook al weer volgeboekt. Maar gelukkig zijn er nog genoeg workshops waar wel wat ruimte is. Daarbij “gouwe ouwe” zoals hoe je aan full-text artikelen komt, hoe je factchecker wordt of hoe je slimmer zoekt in Delpher, maar ook een paar nieuwe zoals AI-oplossingen voor gegevensbescherming bij overheden, grote hoeveelheden tekst analyseren als data of aan de slag met generatieve AI in de mediatheek.
Maar maak je geen zorgen als workshops volgeboekt zijn, want de parallel gegeven lezingen zijn zeker zo interessant. Heel wat workshopbezoekers zullen zelfs nog heftig in dubio zijn of ze toch niet liever naar lezingen hadden gewild. Maar in ons nieuwe aanmeldsysteem kun je eerder gemaakte programmakeuzes gelukkig achteraf nog zelf wijzigen. Over keuzestress gesproken.
Beoordeling van lezingen en workshops
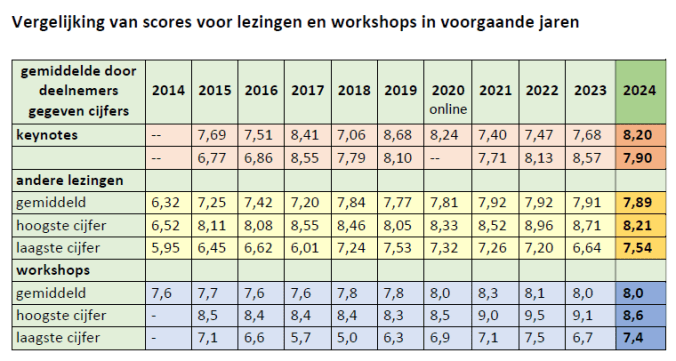
De evaluaties van dit jaar hebben we intussen bekeken. Het doet ons genoegen dat de deelnemers dit jaar weer overwegend positieve beoordelingen gaven aan de lezingen en workshops die we aanboden. Als we vergelijken met voorgaande jaren, zien we dat de hoogste scores wel eens hoger zijn geweest, maar dat de laagste scores – op één uitzondering na – altijd lager waren dan dit jaar. Dus geen negatieve uitschieters en de gemiddelde scores op een hoog niveau.
Daarbij willen we ook de toppers nog even in het zonnetje zetten. Bij de lezingen waren dat ex aequo de lezingen van Michiel van der Meer (keynote over de rol van large language models in informatieverwerking), Fulco Blokhuis (over “AI en IE” – Intellectueel Eigendom) en Daniel Canter (over “ASML’s Taxonomy Adventure”), met alle drie een gemiddelde score van 8.2. Bij de workshops was dat – evenals vorig jaar – die van Annique Mossou (over “Geolocation zoals Bellingcat dat doet”), met een gemiddelde score van 8,6. Runners-up waren dit jaar Daan Damen (over “de waarde van AI voor de culturele sector”) en Shannon van Muijden & Ruben Schalk (“Werken met het termennetwerk”), beide workshops met een gemiddelde van 8,3.
Resultaten van andere aspecten uit de evaluatie houdt u nog even van ons tegoed
Elisabeth Bik strijdt tegen wetenschapsfraude

Interview met keynote spreker Elisabeth Bik in vakblad IP (2023-2).
| Naar schatting honderdduizend papers heeft ze inmiddels gescreend. Daarmee hoopt ze misstanden in de wetenschap tegen te gaan. ‘Soms zien plaatjes er zo fout uit dat ik me niet kan voorstellen dat niemand anders het ziet.’ |
Wil je Elisabeth Bik 16 maart ook live horen? Aanmelden kan nog steeds.


Reijer Passchier over de macht van Big Tech

[In het nieuwste digitale nummer van IP staat een interview met spreker Reijer Passchier. Hieronder is de tekst ook te lezen.]





Explainable AI volgens Nava
[In het nieuwste digitale nummer van IP staat een interview met keynote spreker Nava Tintarev. Hieronder is de tekst ook al te lezen.]





De IKEA Knowledge Graph
Dit jaar is er in het lezingenprogramma weer eens wat meer aandacht voor het vindbaar maken van informatie door middel van “kennisorganisatiesystemen”. Dat is de wat sjiekere benaming voor wat we vroeger onderwerpsontsluiting plachten te noemen. Er is zowel een lezing over taxonomieën als eentje over “knowledge graphs”. Over die eerste lezing hadden we het eerder al; hier meer over die tweede.
 Katariina Kari personificeert een interessante combinatie van competenties: uitvoerend musicus en ITer, en daarbij specifiek het semantisch web. Ze combineerde dat eerder al in het realiseren van de digitale transformatie voor klassieke muziek. Na verantwoordelijk te zijn geweest voor de “Fashion Knowledge Graph” van de grote internationale online modeketen Zalando, werkt ze nu aan de knowledge graph van IKEA.
Katariina Kari personificeert een interessante combinatie van competenties: uitvoerend musicus en ITer, en daarbij specifiek het semantisch web. Ze combineerde dat eerder al in het realiseren van de digitale transformatie voor klassieke muziek. Na verantwoordelijk te zijn geweest voor de “Fashion Knowledge Graph” van de grote internationale online modeketen Zalando, werkt ze nu aan de knowledge graph van IKEA.
Als informatieprofessionals kennen we intussen natuurlijk wel de principes van wat een knowledge graph is. Maar het is goed om eens te horen welke achterliggende architectuur daar in de praktijk voor ontwikkeld kan worden, zeker als dat bij zo’n groot alom bekend bedrijf als IKEA is. Katariina gaat er in haar lezing op in hoe zij daarvoor een drie-lagen-model toepast.  Dat is ontleend aan de GIST upper ontology for the enterprise. In een artikel in Medium heeft ze dat vorig jaar al eens beschreven. In de eerste plaats zijn er de “soorten dingen” waar het bij het bedrijf om draait. Dat zal vaak maar een beperkt aantal zijn – bij IKEA beschreven met circa 100 centraal beheerde concepten. Die vormen als het ware de “ontologie” met de definitie van klassen en eigenschappen. Daaronder volgen de individuele “dingen”. Eerst in een laag van de onderwerpscategorieën waartoe die dingen behoren. Denk bijvoorbeeld aan iets als boekenkasten. Bij IKEA ligt hun aantal in de duizenden. En daaronder de individuele dingen/produkten zelf, waarvan het aantal bij IKEA – het zal niet verwonderen – wel in het miljoen loopt. Denk daarbij aan iets als “BILLY boekenkast wit 80x28x202 cm”.
Dat is ontleend aan de GIST upper ontology for the enterprise. In een artikel in Medium heeft ze dat vorig jaar al eens beschreven. In de eerste plaats zijn er de “soorten dingen” waar het bij het bedrijf om draait. Dat zal vaak maar een beperkt aantal zijn – bij IKEA beschreven met circa 100 centraal beheerde concepten. Die vormen als het ware de “ontologie” met de definitie van klassen en eigenschappen. Daaronder volgen de individuele “dingen”. Eerst in een laag van de onderwerpscategorieën waartoe die dingen behoren. Denk bijvoorbeeld aan iets als boekenkasten. Bij IKEA ligt hun aantal in de duizenden. En daaronder de individuele dingen/produkten zelf, waarvan het aantal bij IKEA – het zal niet verwonderen – wel in het miljoen loopt. Denk daarbij aan iets als “BILLY boekenkast wit 80x28x202 cm”.

Illustration taken from:
https://medium.com/flat-pack-tech/ikeas-knowledge-graph-and-why-it-has-three-layers-a38fca436349
Alleen de concepten voor de eerste twee lagen worden echt door mensen bedacht en bestaan uit gecontroleerd vocabulaire. Voor de grote massa die daaronder volgt, worden de termen automatisch gegenereerd uit de databronnen waarin de gegevens voor die produkten toch al aanwezig zijn. Hoe je dat praktisch kunt organiseren met verantwoordelijkheden, auteurschap en opslag, zal in de lezing ook aan de orde komen.
Deze knowledge graph is (ook) op de klanten van IKEA gericht, om hen een betere digitale “beleving” te kunnen bieden. Voor de interne logistiek van individuele items wordt hij niet gebruikt.
