 Het 20-jarig jubileum van Facebook markeert een belangrijke mijlpaal in de evolutie van sociale media. Oorspronkelijk in 2004 gelanceerd als “smoelenboek” voor Harvard-studenten, werd Facebook al snel een dominante kracht in het verbinden van mensen over de hele wereld.
Het 20-jarig jubileum van Facebook markeert een belangrijke mijlpaal in de evolutie van sociale media. Oorspronkelijk in 2004 gelanceerd als “smoelenboek” voor Harvard-studenten, werd Facebook al snel een dominante kracht in het verbinden van mensen over de hele wereld. Dat veroorzaakte een revolutie in de manier waarop we met elkaar omgaan, informatie delen en communiceren.
Dat veroorzaakte een revolutie in de manier waarop we met elkaar omgaan, informatie delen en communiceren.  Facebook is in Nederland het populairste sociale medium. Zo’n 7,9 miljoen Nederlanders gebruiken het. En velen van hen nog heel intensief ook.
Facebook is in Nederland het populairste sociale medium. Zo’n 7,9 miljoen Nederlanders gebruiken het. En velen van hen nog heel intensief ook.
Geen wonder dat steeds meer onderzoeken aantonen dat Facebook ‘real life’ consequenties heeft. Want naarmate het platform is gegroeid en geëvolueerd in de afgelopen twee decennia, zijn ook de uitdagingen waarmee Facebook wordt geconfronteerd toegenomen.
Verspreiding van schadelijk materiaal
Tijdens een recente hoorzitting hebben Amerikaanse senatoren Mark Zuckerberg, de CEO van Meta, het moederbedrijf van Facebook en ook eigenaar van Whatsapp, beschuldigd van het verspreiden van schadelijk materiaal op het platform. Zoals desinformatie, stalking, haatspraak en ander schadelijk materiaal dat zich heeft kunnen verspreiden door agressieve algoritmen die zijn gericht op het maximaliseren van advertentie-inkomsten. Deze algoritmen geven prioriteit aan betrokkenheid, wat vaak leidt tot de versterking van verdeeldheid zaaiende en sensationele inhoud, in plaats van het bevorderen van betekenisvolle interacties.
 Deze erosie van de oorspronkelijke magische formule van sociale media, waarin persoonlijke interacties werden vermengd met massale communicatie, heeft geleid tot groeiende zorgen over de negatieve impact van sociale media op de samenleving. De verspreiding van desinformatie en schadelijke inhoud heeft bijgedragen aan polarisatie, misinformatie en zelfs geweld in de echte wereld.
Deze erosie van de oorspronkelijke magische formule van sociale media, waarin persoonlijke interacties werden vermengd met massale communicatie, heeft geleid tot groeiende zorgen over de negatieve impact van sociale media op de samenleving. De verspreiding van desinformatie en schadelijke inhoud heeft bijgedragen aan polarisatie, misinformatie en zelfs geweld in de echte wereld.
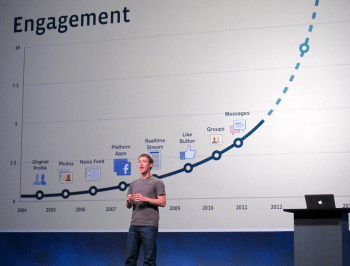
 Ondanks deze uitdagingen blijft Meta, het moederbedrijf van Facebook, ook eigenaar van Messenger, WhatsApp en Instagram, indrukwekkende financiële resultaten behalen. Meta is momenteel $ 742 miljard waard en zal naar verwachting in 2023 een omzet van ongeveer $ 133 miljard realiseren. Echter, naast deze financiële successen, zijn er ernstige scheuren ontstaan in het digitale plein. Deze scheuren vertegenwoordigen de groeiende desillusie met traditionele sociale mediaplatforms en de dringende behoefte aan alternatieve ruimtes voor online interactie.
Ondanks deze uitdagingen blijft Meta, het moederbedrijf van Facebook, ook eigenaar van Messenger, WhatsApp en Instagram, indrukwekkende financiële resultaten behalen. Meta is momenteel $ 742 miljard waard en zal naar verwachting in 2023 een omzet van ongeveer $ 133 miljard realiseren. Echter, naast deze financiële successen, zijn er ernstige scheuren ontstaan in het digitale plein. Deze scheuren vertegenwoordigen de groeiende desillusie met traditionele sociale mediaplatforms en de dringende behoefte aan alternatieve ruimtes voor online interactie.
 Dit is belangrijk omdat sociale mediaplatforms inmiddels integrale onderdelen van de moderne samenleving zijn geworden, die de publieke discussie beïnvloeden, politieke meningen vormen en de geestelijke gezondheid beïnvloeden. De ongecontroleerde verspreiding van schadelijke inhoud vormt een bedreiging voor de democratie en sociale cohesie, waardoor het noodzakelijk is om de onderliggende problemen van sociale mediaplatforms aan te pakken.
Dit is belangrijk omdat sociale mediaplatforms inmiddels integrale onderdelen van de moderne samenleving zijn geworden, die de publieke discussie beïnvloeden, politieke meningen vormen en de geestelijke gezondheid beïnvloeden. De ongecontroleerde verspreiding van schadelijke inhoud vormt een bedreiging voor de democratie en sociale cohesie, waardoor het noodzakelijk is om de onderliggende problemen van sociale mediaplatforms aan te pakken.
Op zoek naar nieuwe plekken om verhalen uit te wisselen
 Als reactie op deze uitdagingen zoeken mensen steeds vaker alternatieve platforms op waar ze verhalen kunnen uitwisselen en contact kunnen leggen met anderen zonder te worden onderworpen aan hetzelfde niveau van manipulatie en schade. Deze platforms geven prioriteit aan privacy, betekenisvolle interacties en gemeenschapsvorming boven statistieken over betrokkenheid en stijgende advertentie-inkomsten.
Als reactie op deze uitdagingen zoeken mensen steeds vaker alternatieve platforms op waar ze verhalen kunnen uitwisselen en contact kunnen leggen met anderen zonder te worden onderworpen aan hetzelfde niveau van manipulatie en schade. Deze platforms geven prioriteit aan privacy, betekenisvolle interacties en gemeenschapsvorming boven statistieken over betrokkenheid en stijgende advertentie-inkomsten.
Enkele van de nieuwe populaire plekken waar mensen samenkomen om verhalen uit te wisselen zijn:
- Berichten-apps:
Platforms zoals WhatsApp, Signal https://signal.org/ en Telegram https://telegram.org/ bieden privé, versleutelde berichtenfuncties waarmee gebruikers contact kunnen leggen met vrienden en familie zonder de kritiek van algoritmen of de verspreiding van schadelijke inhoud. Telegram en Signal zijn als reactie op META’s overheersende positie op de markt gekomen. - Niche gemeenschappen:
Online forums en op gemeenschap gebaseerde platforms zoals Reddit https://www.reddit.com/?rdt=59952 , Discord https://discord.com/ en Clubhouse https://www.clubhouse.com/ bieden ruimtes voor gelijkgestemde individuen om samen te komen en specifieke interesses of onderwerpen te bespreken in een meer gecontroleerde omgeving. - Op abonnement gebaseerde platforms:
Platforms zoals Patreon https://www.patreon.com/nl-NL en Substack https://substack.com/ stellen makers in staat om hun inhoud rechtstreeks bijvan hun publiek ten gelde te maken, waardoor de afhankelijkheid van advertentie-inkomsten wordt verminderd en mogelijk meer oprechte interacties worden bevorderd. - Gedecentraliseerde sociale netwerken:
Opkomende platforms gebaseerd op blockchaintechnologie, zoals Steemit https://steemit.com/ en Minds, https://www.minds.com/ streven ernaar sociale media te decentraliseren, waardoor gebruikers meer controle krijgen over hun gegevens en inhoud en de invloed van algoritmen en gecentraliseerde autoriteiten wordt verminderd.
Het 20-jarig jubileum van Facebook markeert een kritiek moment om na te denken over de impact en toekomst van sociale media op de samenleving. Naarmate de zorgen over de verspreiding van schadelijke inhoud en de erosie van betekenisvolle interacties blijven groeien, zoeken mensen steeds vaker naar alternatieve platforms die privacy, authenticiteit en gemeenschapsvorming prioriteren. Het is essentieel dat beleidsmakers, techbedrijven en gebruikers samenwerken om deze uitdagingen aan te pakken en te streven naar een veiligere en verantwoorde digitale omgeving.
Peter van Gorsel



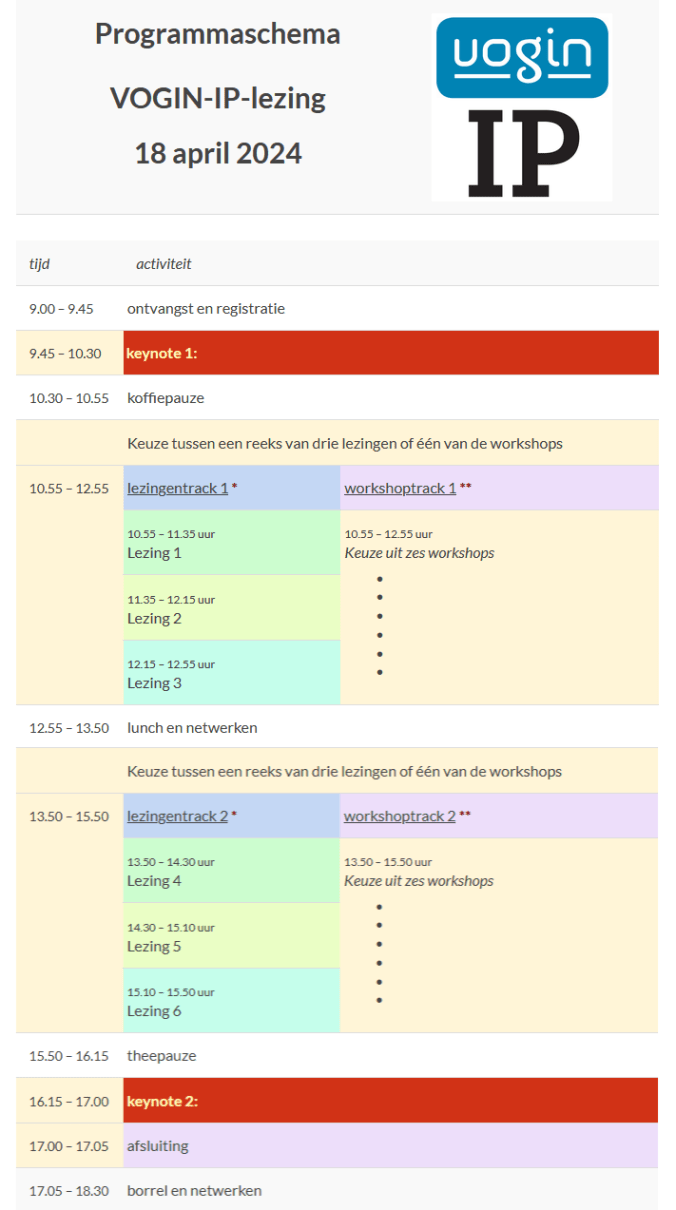

 Vandaag hebben we ook een nieuwsbrief uitgestuurd, waarin we deze datum aankondigden. Als u die gemist hebt, kunt u hem
Vandaag hebben we ook een nieuwsbrief uitgestuurd, waarin we deze datum aankondigden. Als u die gemist hebt, kunt u hem 
 In de rondjes hierboven zie je antwoorden op drie van onze vragen. De derde vraag hadden we dit jaar toegevoegd, omdat we merkten dat lang niet alle deelnemers hun deelnamecertificaat meenemen. De uitkomst daarvan maakt in elk geval dat we ons nader zullen beraden of we nog met die certificaten door moeten gaan.
In de rondjes hierboven zie je antwoorden op drie van onze vragen. De derde vraag hadden we dit jaar toegevoegd, omdat we merkten dat lang niet alle deelnemers hun deelnamecertificaat meenemen. De uitkomst daarvan maakt in elk geval dat we ons nader zullen beraden of we nog met die certificaten door moeten gaan.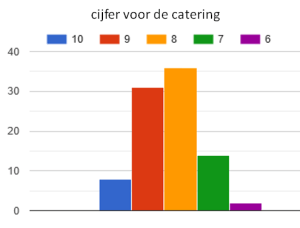 De cijfers die jullie voor de catering gaven – met een gemiddelde ruim boven de 8 – stemmen ons in eerste instantie redelijk tevreden. Maar als we naar de open opmerkingen bij deze vraag kijken, zien we ook wel heel uiteenlopende en soms tegengestelde meningen. Een kleine selectie:
De cijfers die jullie voor de catering gaven – met een gemiddelde ruim boven de 8 – stemmen ons in eerste instantie redelijk tevreden. Maar als we naar de open opmerkingen bij deze vraag kijken, zien we ook wel heel uiteenlopende en soms tegengestelde meningen. Een kleine selectie:
 met 7,9 was het vrijwel gelijk aan de gemiddelden van de afgelopen twee jaar.
met 7,9 was het vrijwel gelijk aan de gemiddelden van de afgelopen twee jaar. Met een gemiddeld cijfer van 9,1 sprong de workshop over geolocatie van Bellingcat-docent Annique Mossou er dit jaar duidelijk uit. De enige keer dat een workshop al eens hoger gewaardeerd werd – vorig jaar – telt niet serieus mee, want dat cijfer was gebaseerd op de respons van maar twee (!) deelnemers, terwijl het cijfer van Annique een gemiddelde van twaalf respondenten was. Het is wel aardig om dit summiere overzicht nog even te besluiten met een paar van de (louter enthousiaste) opmerkingen die deelnemers over deze workshop maakten.
Met een gemiddeld cijfer van 9,1 sprong de workshop over geolocatie van Bellingcat-docent Annique Mossou er dit jaar duidelijk uit. De enige keer dat een workshop al eens hoger gewaardeerd werd – vorig jaar – telt niet serieus mee, want dat cijfer was gebaseerd op de respons van maar twee (!) deelnemers, terwijl het cijfer van Annique een gemiddelde van twaalf respondenten was. Het is wel aardig om dit summiere overzicht nog even te besluiten met een paar van de (louter enthousiaste) opmerkingen die deelnemers over deze workshop maakten.



 De meeste deelnemers zullen de OBA, de Openbare Bibliotheek Amsterdam wel kennen. Zo niet: het is op het Oosterdokseiland, 10 minuten lopen oost van het Centraal Station. Kijk zonodig nog even op Google Maps. Via
De meeste deelnemers zullen de OBA, de Openbare Bibliotheek Amsterdam wel kennen. Zo niet: het is op het Oosterdokseiland, 10 minuten lopen oost van het Centraal Station. Kijk zonodig nog even op Google Maps. Via 
 Het is het handigst om met lift of roltrap naar de 6de etage te gaan en daar de trap naar het theater te nemen. Om de aanmelding wat te stroomlijnen, splitsen we de deelnemers halverwege die trap op alfabet: A-K en L-Z. Bovenaan die trappen kun je je badge en verdere paperassen ophalen en vast een kopje koffie nemen.
Het is het handigst om met lift of roltrap naar de 6de etage te gaan en daar de trap naar het theater te nemen. Om de aanmelding wat te stroomlijnen, splitsen we de deelnemers halverwege die trap op alfabet: A-K en L-Z. Bovenaan die trappen kun je je badge en verdere paperassen ophalen en vast een kopje koffie nemen.













