
Iedereen heeft het ineens over ChatGPT, het programma dat onwaarschijnlijk goed lopende, plausibel klinkende, coherente (Engelse) teksten over willekeurig welk onderwerp kan schrijven, en zelfs hele stukken computercode kan genereren. Daardoor komen op dit moment op alle media zowel grappige voorbeelden als serieuze toepassingen langs. Zo’n toepassing – met bezorgde kanttekening – is bijvoorbeeld dat studenten door het systeem essays kunnen laten schrijven, die voldoendes opleveren als ze die bij een toets inleveren. [1], [2]

ChatGPT werkt op basis van een zogenaamd LLM, een “large language model”, een taalmodel dat getraind is met gigantische hoeveelheden tekst. Zoals uit de naam al blijkt, gebruikt ChatGPT daarvoor de GPT-3 software (Generative Pre-trained Transformer – versie 3) die twee jaar geleden, als opvolger van “BERT“, een ware revolutie in AI-land teweeg bracht. Bij de VOGIN-IP-lezing 2021 kwam GPT-3 al aan de orde in de keynote van Antal van den Bosch.
In dit stuk geven we verder vooral voorbeelden die direct op ons vakgebied aansluiten. Zo wordt soms al gesteld dat je net zo goed een vraag aan ChatGPT kunt stellen als aan een klassieke zoekmachine. Inderdaad krijg je hiermee in de meeste gevallen ook onmiddellijk een heel plausibel antwoord. Alleen is het even de vraag hoe betrouwbaar dat antwoord is, waar dat antwoord vandaan komt, hoe ChatGPT dat antwoord bij elkaar geharkt heeft uit losse tekstfragmentjes uit het gigantische tekstcorpus waarmee het systeem getraind is (de “provenance”-vraag). Verderop volgen nog wel wat voorbeelden van dergelijke fraai klinkende teksten. Wellicht moeten we onze keynote spreekster Nava Tintarev op 16 maart maar eens vragen of dat provenance-probleem wellicht kan worden opgelost met de systemen die in haar lezing aan de orde komen: “explainable AI-systems” die zelf aan gebruikers kunnen uitleggen hoe ze tot hun recommandaties en antwoorden komen.
“Provenance” is overigens niet het enige probleem met betrekking tot ChatGPT om je zorgen over te maken. Een volgende complicatie is de verwachting dat heel veel van dit soort AI-gegenereerde teksten ook weer hun weg zullen vinden op internet en daarmee terecht zullen komen in de zoekresultaten uit gewone zoekmachines. Nog weer een stapje verder dan dergelijke directe vervuiling van zoekresultaten, gaat de verwachting dat zulke door ChatGPT gegenereerde teksten bovendien terechtkomen in het materiaal waarmee taalmodellen als ChatGPT nu juist getraind worden, leidend tot een soort Baron von Münchhausen-effect.
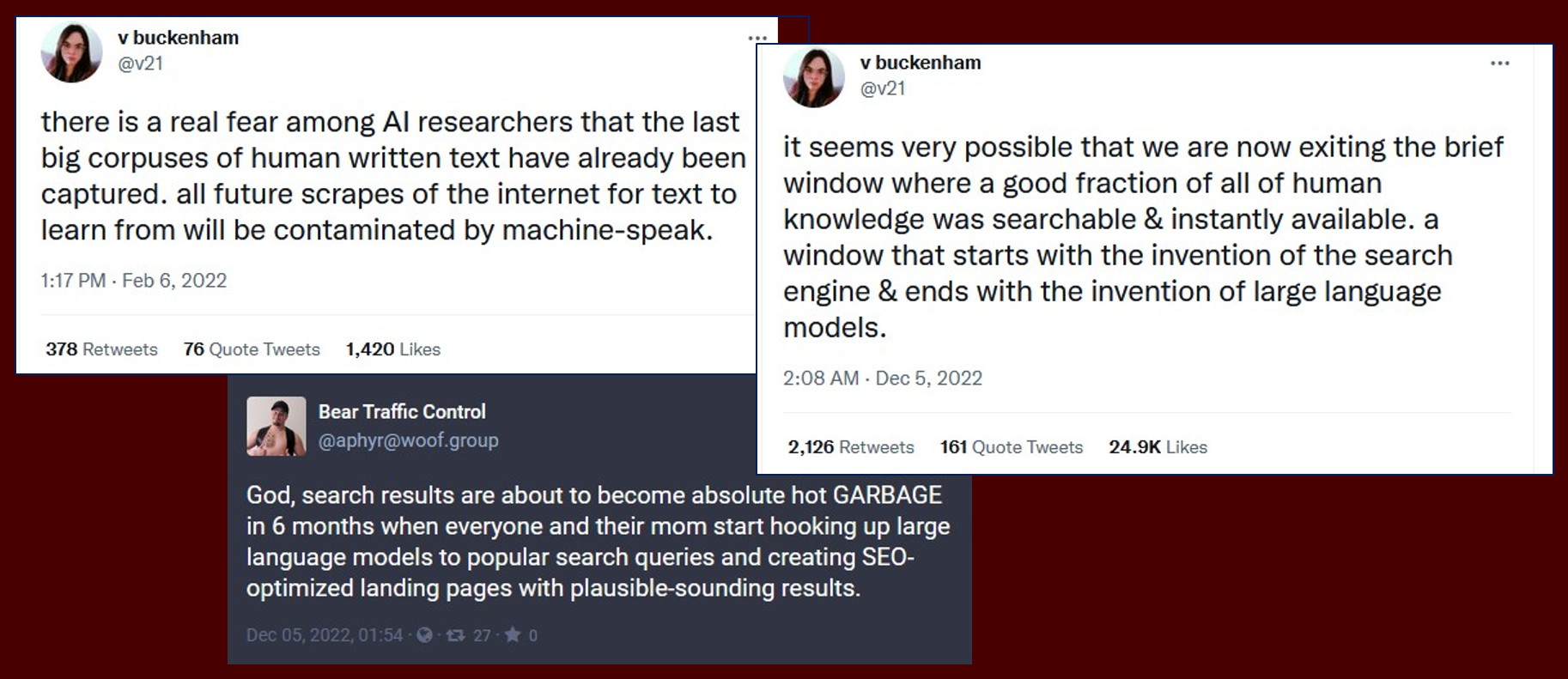
Overigens wekt ChatGPT de indruk zich zelf ook “bewust” te zijn van de gevaren die dergelijk hergebruik met zich meebrengt (als je hem daarnaar vraagt).

Als je ChatGPT vraagt een artikel te schrijven met een referentielijst, ziet het resultaat er heel vertrouwenwekkend uit; de literatuurverwijzingen bestaan uit combinaties van plausibel klinkende titels en tijdschrift- en auteursnamen. Alleen zijn ze net zo fake als al die profielfoto’s van nepaccounts, die met deepfake technologie gegenereerd worden. “It is literally bullshitting”.

Het is trouwens opmerkelijk hoeveel informatie over het trainen van AI-systemen – kennelijk – in de trainingsdata verwerkt zat. Op vragen over de data waarmee het programma zelf getraind is, weet ChatGPT namelijk heel plausibel klinkende antwoorden te genereren .
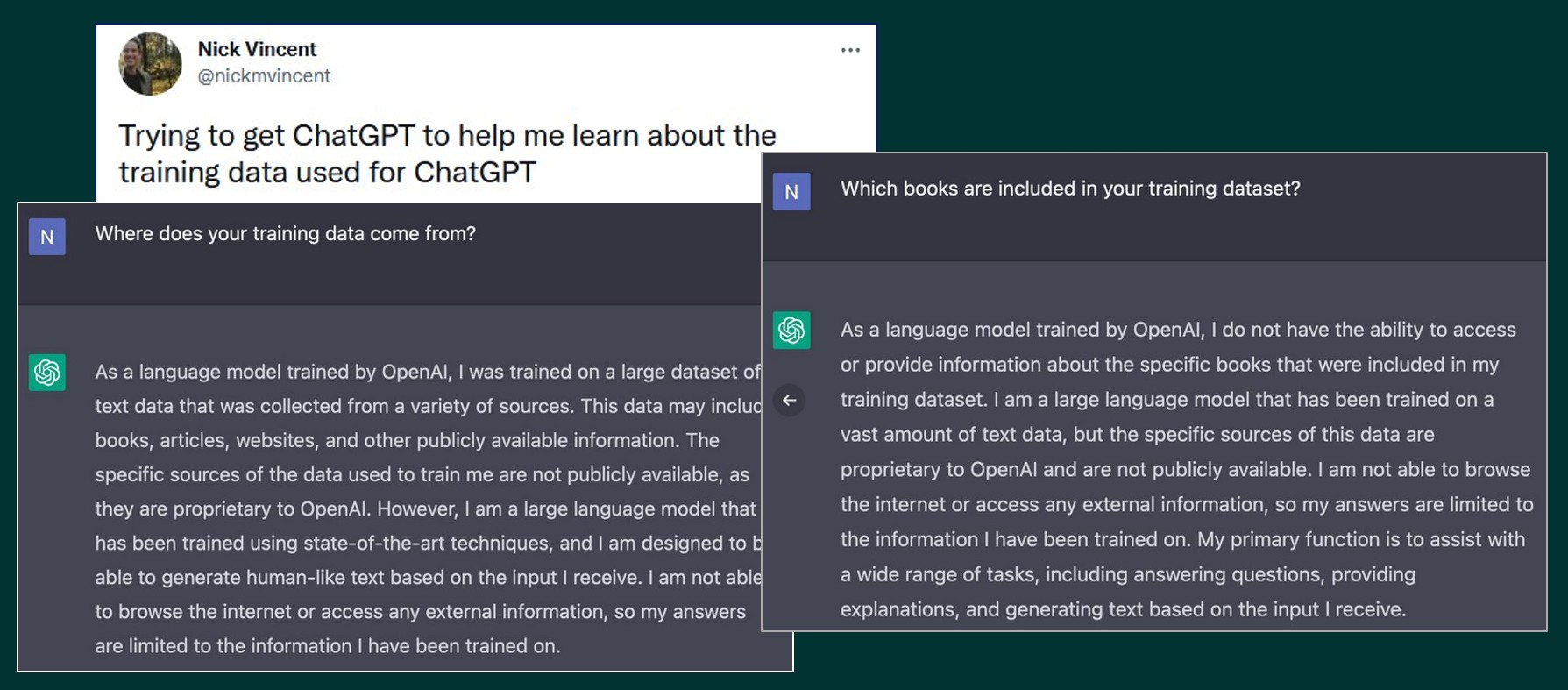
Zo geeft ChatGPT ook antwoord op de vraag of het in staat is artikelen en antwoorden in Wikipedia-stijl te genereren, omdat het systeem ook met dergelijke artikelen getraind is. Dat is langzamerhand wel heel erg “meta” …. 😉

Bij die artikelen komen ook meteen al lijstjes verwijzingen. En structuur en templates van Wikipedia artikelen komen er ook uit.

Speciaal voor de Wikipedia nerds onder onze lezers hier een voorbeeld van de kant-en-klare Wikipedia Templates die ChatGPT hierbij kan genereren. Als je dit voorbeeld ziet, verbaast het niet meer dat ChatGPT ook in staat is om redelijk bruikbare code voor diverse populaire programmeertalen te genereren [vb].

Wat deze laatste voorbeelden ook duidelijk maken, is dat dit soort geavanceerde chatbots een bron als Wikipedia makkelijk kunnen vervuilen met een overmaat aan moeilijk te herkennen fake-teksten. Ik vrees dat er extra werk aan de winkel komt voor serieuze menselijke wikipedians. Of zou ChatGPT zelf wellicht getraind kunnen worden om dit soort fake bijdragen automatisch te herkennen?
Eric Sieverts
Aanvulling d.d. 21/12/2022:
Gisteren heeft Jan Scholtes (in 2017 spreker op ons congres) een blogpost met een uitgebreide beschrijving van voorgeschiedenis, werking en problemen van ChatGPT op LinkedIn geplaatst. Ondanks dat het verhaal deels wel wat technisch is, is het zeker een aanrader.
[Op 10/12/2022 waren nog enkele kleine aanvullingen in deze tekst toegevoegd.]
De bij dit artikel afgebeelde voorbeelden zijn ontleend aan berichten die gepost waren op Twitter en op Mastodon.
