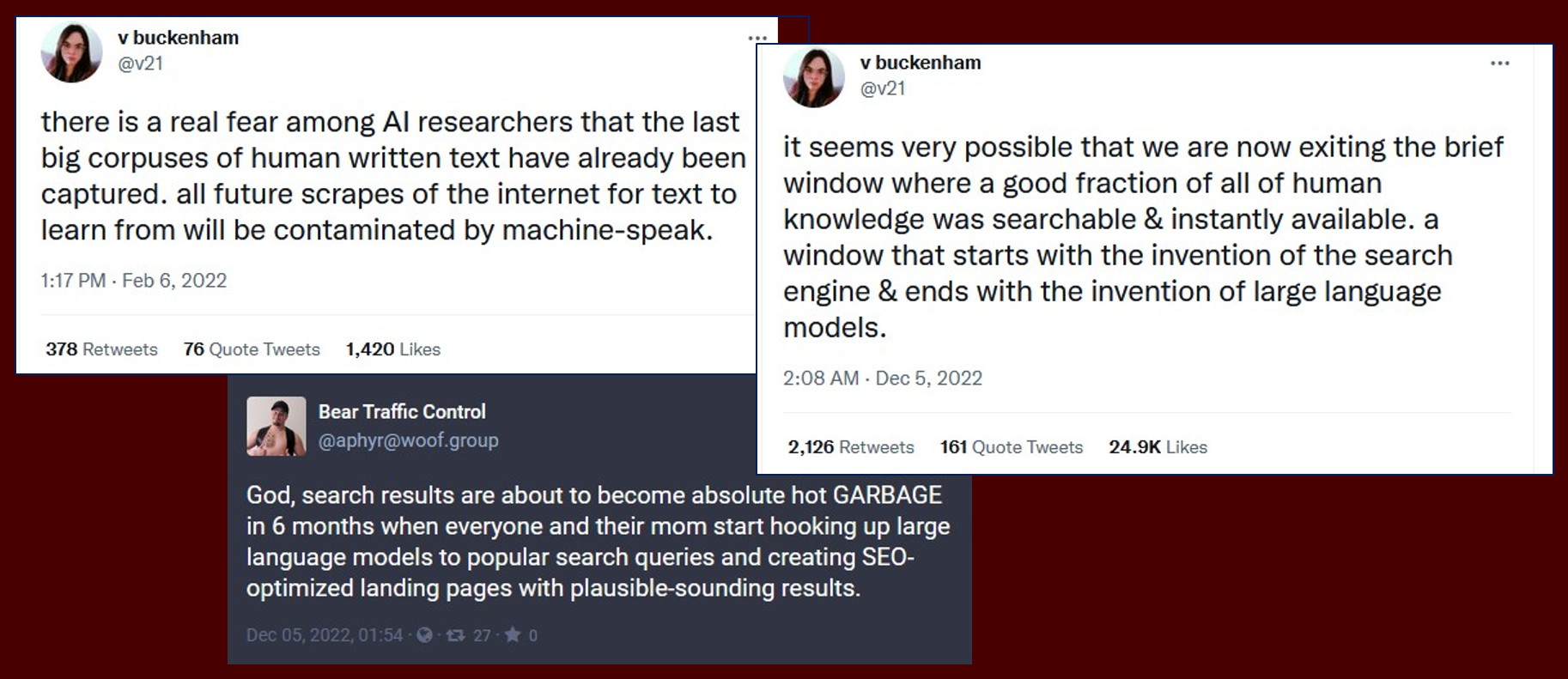
Er zullen weinig informatieprofessionals zijn, die de laatste maanden het nieuws over kunstmatige intelligentie (AI) niet met belangstelling gevolgd hebben. Large Language Models, generatieve AI en in het bijzonder OpenAI’s programma ChatGPT en Google-applicatie Bard hebben de talige kant van AI het afgelopen jaar een enorme boost gegeven. Voor allerlei toepassingen blijken die systemen verbazingwekkende resultaten op te leveren.
Aan de negatieve kanten van deze toepassingen wordt ook wel regelmatig aandacht besteed, zoals aan de vervuiling van het informatieaanbod met zogenaamde “hallucinaties” van ChatGPT en met domweg foute antwoorden. Een vervuiling die gewone zoekmachines dan ook weer als zodanig moeten onderkennen. Een negatief aspect waarop in het nieuws wat minder nadruk wordt gelegd, is de ecologische voetafdruk van deze technieken. Die is namelijk beslist niet verwaarloosbaar. Zowel het vooraf trainen van de gebruikte taalmodellen als het verwerken van elk request dat op dergelijke systemen wordt losgelaten, doet een enorm beroep op processor-capaciteit. Voor de servers waarop dit soort systemen draaien moet daarom al extreme koeling worden toegepast.
Aan een recent onderzoek van Kasper Groes Albin Ludvigsen, een Deense data scientist, ontlenen we hier wat gegevens over de CO2 uitstoot die met dat energiegebruik gepaard gaat.
“Training OpenAI’s GPT-4 model may have emitted upwards of 15,000 tons CO2e, according to my estimates that are based on leaked data.”
“In comparison, it’s estimated that training GPT-3 [de vorige versie] emitted 552 tons CO2e.”
“15,000 tons is roughly the same as the annual emissions of 938 Americans.”
Een andere bron van informatie over het energiegebruik van dit soort generatieve AI biedt Columbia University in AI’s Growing Carbon Footprint. Zij schrijven:
“To process and analyze the vast amounts of data, large language models need tens of thousands of advanced high-performance chips for training and, once trained, for making predictions about new data and responding to queries.”
“In 2018, a large language model had 100 million parameters. GPT-2, launched in 2019, had 1.5 billion parameters; GPT-3 at 100 times larger, had 175 billion parameters; no one knows how large GPT-4 is. Google’s PaLM large language model, which is much more powerful than Bard, had 540 billion parameters.”
Zij citeren ook een andere recente studie die berekende dat het trainen van GPT-3 (de vorige versie dus nog, met het taalmodel met 175 miljard parameters) 1287 MWh aan electriciteit gebruikte, wat resulteerde in emissies van 502 ton CO2, het equivalent van een jaar lang rijden met 112 benzineauto’s. Volgens de cijfers uit de Deense studie zou dat voor GPT-4 dus nog eens bijna 30x zoveel kunnen zijn.
En dat is dan alleen nog het trainen. Google schatte dat van de totale energie die in AI gebruikt wordt, maar 40% op rekening komt van het trainen en 60% gebruikt wordt voor “inference”, het uit taalmodellen afleiden van antwoorden en het genereren van de tekst van reacties op vragen en opdrachten van gebruikers. Het verwerken van een enkele vraag vergt natuurlijk veel en veel minder energie dan zo’n trainingssessie. Ook al moet het model frequent hertraind worden, staat dat niet in verhouding tot het zeer vele malen grotere aantal te beantwoorden vragen. Het genereren van zulke antwoorden verbruikt ook wel 100 keer zoveel energie als het gewoon beantwoorden van een zoekvraag met Google. Bovendien heeft ChatGPT intussen al meer dan 200 miljoen actieve gebruikers die een tijdlang heel veel niet zo serieuze test- en fun-requests op het systeem hebben afgevuurd. Hoewel ChatGPT verreweg het bekendste systeem voor generatieve AI is, zijn er intussen nog veel meer van dergelijke systemen actief, die ook allemaal energie verstoken.
Nu generatieve AI hard op weg lijkt te zijn om als energieverspiller de plaats over te nemen van een vorige notoire verspiller als blockchain, is energieverbruik dus wel een dingetje om bij stil te staan, voordat we voor elke kleinigheid van generatieve AI gebruik gaan maken. Als we cijfers over het maandelijks aantal ChatGPT gebruikers mogen geloven, die Nerdynav vorige week publiceerde, schijnt de grootste hype overigens alweer een beetje voorbij te zijn. Na een piek in april lijkt het gebruik intussen al aardig te stabiliseren.

Eric Sieverts
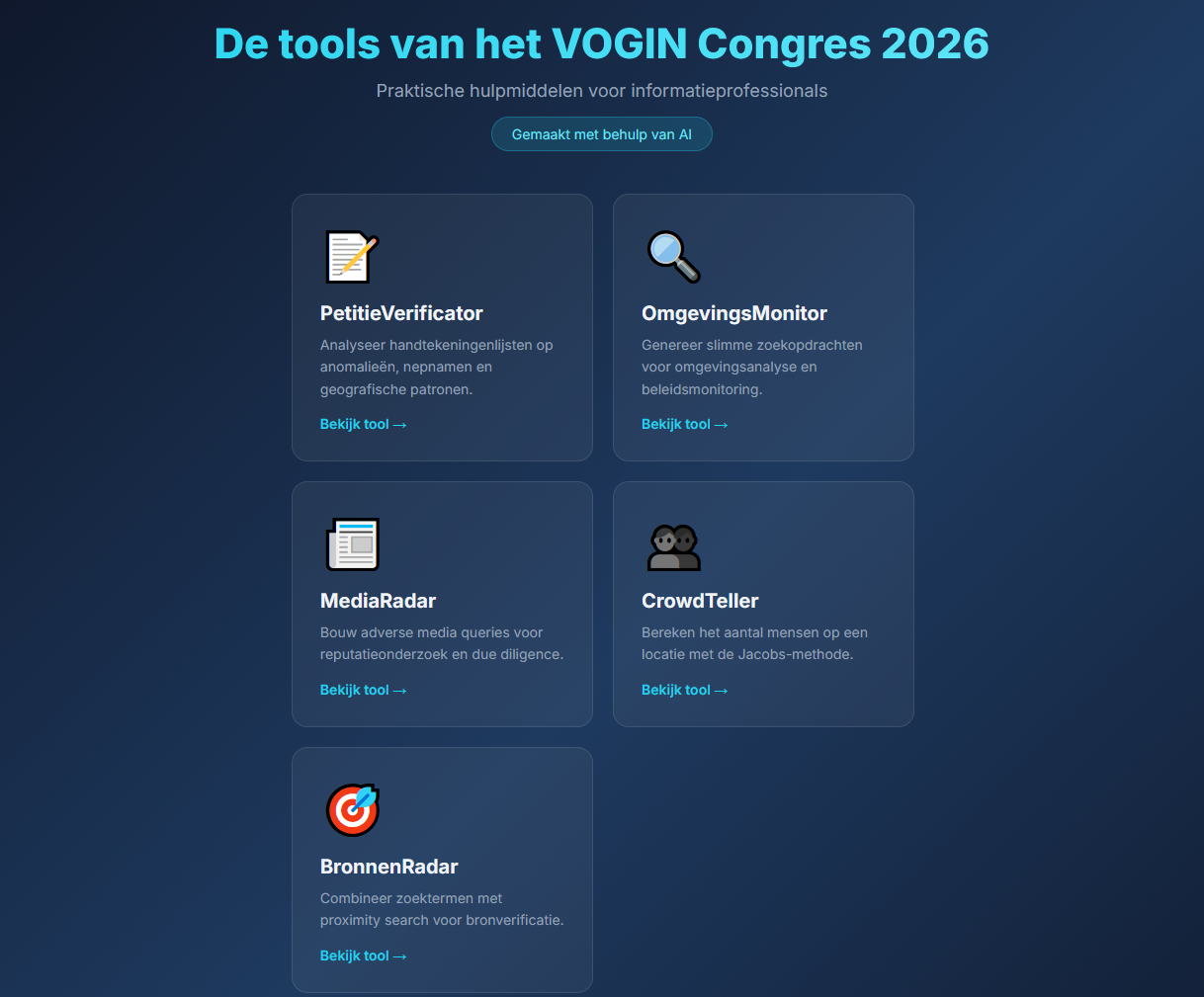 Vorige week was Henk van Ess een van de sprekers op VOGIN’s “omgevingscongres”. Daar liet hij zien hoe je met AI AI kunt genereren – onder meer hoe je kunt “prompten” zonder zelf te hoeven prompten. Hij liet al weten dat hij op 9 april bij de VOGIN-IP-lezing aanwezig zal zijn om dat ook te laten zien.
Vorige week was Henk van Ess een van de sprekers op VOGIN’s “omgevingscongres”. Daar liet hij zien hoe je met AI AI kunt genereren – onder meer hoe je kunt “prompten” zonder zelf te hoeven prompten. Hij liet al weten dat hij op 9 april bij de VOGIN-IP-lezing aanwezig zal zijn om dat ook te laten zien.

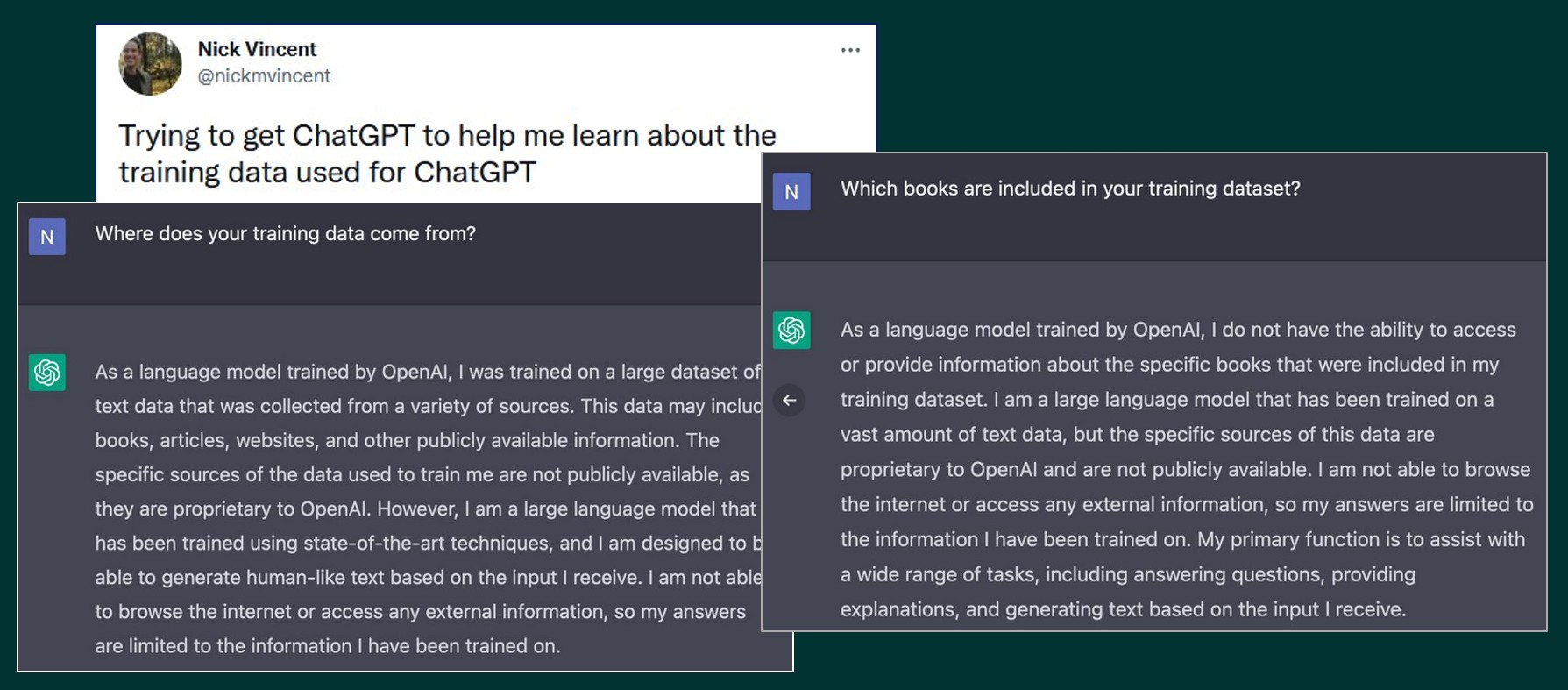
 In een eerdere blogpost getiteld
In een eerdere blogpost getiteld 
 OpenAI, de maker van de ChatGPT software zou
OpenAI, de maker van de ChatGPT software zou