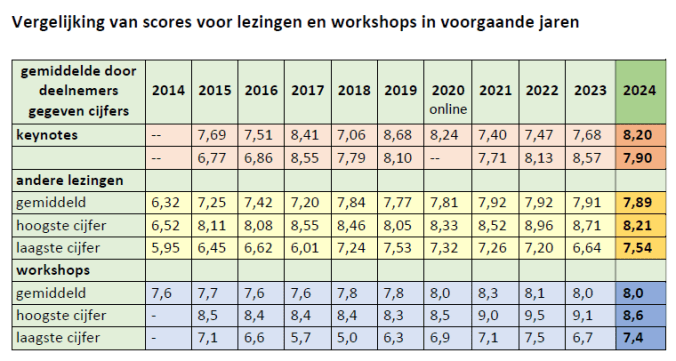
De evaluaties van dit jaar hebben we intussen bekeken. Het doet ons genoegen dat de deelnemers dit jaar weer overwegend positieve beoordelingen gaven aan de lezingen en workshops die we aanboden. Als we vergelijken met voorgaande jaren, zien we dat de hoogste scores wel eens hoger zijn geweest, maar dat de laagste scores – op één uitzondering na – altijd lager waren dan dit jaar. Dus geen negatieve uitschieters en de gemiddelde scores op een hoog niveau.
Daarbij willen we ook de toppers nog even in het zonnetje zetten. Bij de lezingen waren dat ex aequo de lezingen van Michiel van der Meer (keynote over de rol van large language models in informatieverwerking), Fulco Blokhuis (over “AI en IE” – Intellectueel Eigendom) en Daniel Canter (over “ASML’s Taxonomy Adventure”), met alle drie een gemiddelde score van 8.2. Bij de workshops was dat – evenals vorig jaar – die van Annique Mossou (over “Geolocation zoals Bellingcat dat doet”), met een gemiddelde score van 8,6. Runners-up waren dit jaar Daan Damen (over “de waarde van AI voor de culturele sector”) en Shannon van Muijden & Ruben Schalk (“Werken met het termennetwerk”), beide workshops met een gemiddelde van 8,3.
Resultaten van andere aspecten uit de evaluatie houdt u nog even van ons tegoed
- Comment
- Reblog
-
Subscribe
Subscribed
Already have a WordPress.com account? Log in now.
