Uit het nieuwe nummer van IP (2018/2) een Q&A met keynote spreker Ruben Verborgh

.
Je waarschuwt dat blockchain ineens een hype is die overal bij betrokken wordt, of het nu zinnig is of niet. Maar je geeft ook aan dat in het domein van de informatieprofessional toepassingen mogelijk zijn. Wat zijn in het algemeen voorwaarden waaronder een blockchain-oplossing zinnig is?
Het hoofddoel van blockchain is om bindende akkoorden vast te leggen tussen meerdere partijen, zonder dat daarvoor vertrouwen nodig is in elkaar of in een centrale speler. We noemen dit gedistribueerde consensus. Het omgekeerde geldt echter ook: als partijen elkaar wel vertrouwen, of als ze al een centrale plek erkennen, dan hebben we wellicht geen blockchain nodig – zeker niet als er geen consensus nodig is. Bijvoorbeeld, als jij me een officieel bericht wilt sturen, kan je dit gewoon digitaal handtekenen, zonder blockchain.
Belangrijke randvoorwaarden voor zinnig gebruik zijn dus: meerdere partijen, afwezigheid van vertrouwen of autoriteit, en de noodzaak om tot een gezamenlijke waarheid te komen.
In je keynote ga je het hebben over toepassing van blockchain voor Linked Data. Wat maakt dat het daar dan wel zinnig kan zijn?
Linked Data is inherent ook gedistribueerd: elk stukje data kan op een andere plek staan. Blockchain kan dan nuttig zijn om vertrouwen te creëren in zo’n gedecentraliseerd netwerk van data. Omgekeerd kan Linked Data ook helpen met de beschrijving van data en afspraken binnen een blockchain, of met de interoperabiliteit tussen verschillende soorten blockchains. Dat klinkt nog wat ingewikkeld, maar in mijn lezing zal ik dat verder uitleggen.
Je hebt intussen ook een relatie gelegd met recente ideeën van jezelf en van Herbert van de Sompel voor volledig gedecentraliseerde systemen. Bijvoorbeeld een systeem van persoonlijke “datapods” waar ieder zijn eigen gegevens, publicaties, meningen etc. in kan stoppen *. Kun je hier al uitleggen wat dat met elkaar te maken heeft?
Het Web is op enkele jaren tijd sterk gecentraliseerd geraakt: steeds meer data komt in steeds minder verschillende platformen terecht, zoals bijvoorbeeld in Facebook. Langs de ene kant maakt zoiets een hele waaier aan intelligente services over die data mogelijk. Langs de andere kant zijn we zelf geen eigenaar van die intelligentie, en geven we bovendien ook de controle over onze data op. We kunnen ons dus de vraag stellen of dit een rechtvaardige prijs is.
Het idee achter persoonlijke datapods is dat we elk stukje data dat we genereren, in onze eigen opslagplek stoppen. Die bevat niet alleen data en metadata over onszelf en onze activiteiten, maar ook alle interacties met andere informatie. Als ik bijvoorbeeld een commentaar schrijf bij tekst in iemand anders datapod, dan wordt die commentaar bij mij opgeslagen en krijgt die ander bericht daarvan. De grote uitdaging is om toch een soortgelijke gebruikerservaring te bieden als in een gecentraliseerd systeem, ook al zitten deze stukjes data niet meer in één zo’n centraal platform. Voor de uitwisseling en verwerking van gegevens kunnen blockchains dan vertrouwensverbanden opzetten tussen verschillende persoonlijke datapods, onder meer als garantie voor de betrouwbaarheid en authenticiteit van de links tussen die componenten.
* zie: https://ruben.verborgh.org/blog/2017/12/20/paradigm-shifts-for-the-decentralized-web/
en https://www.slideshare.net/hvdsomp/paul-evan-peters-lecture/

 Dit zijn de negen sprekers die 28 maart in acht lezingen aan het woord komen; met linksboven en rechtsonder onze keynote sprekers. In elk geval om te zien is het al een afwisselend gezelschap. Wie preciezer wil weten waar ze het over gaan hebben (en wie ze zijn), moet de teksten op
Dit zijn de negen sprekers die 28 maart in acht lezingen aan het woord komen; met linksboven en rechtsonder onze keynote sprekers. In elk geval om te zien is het al een afwisselend gezelschap. Wie preciezer wil weten waar ze het over gaan hebben (en wie ze zijn), moet de teksten op  Cees Snoek, spreker op de vorige VOGIN-IP-lezing, is vorige week
Cees Snoek, spreker op de vorige VOGIN-IP-lezing, is vorige week  Ruben Verborgh windt zich ook nog wel op over andere dingen dan dat waarvoor hij 28 maart als spreker naar Amsterdam komt. Zo was er veel belangstelling toen hij eind vorige maand in zijn thuishaven Gent fel van leer trok tegen de Amerikaanse ideeën dat net-neutrality op internet beter afgeschaft kon worden. Dit verscheen toen over en van hem op Twitter:
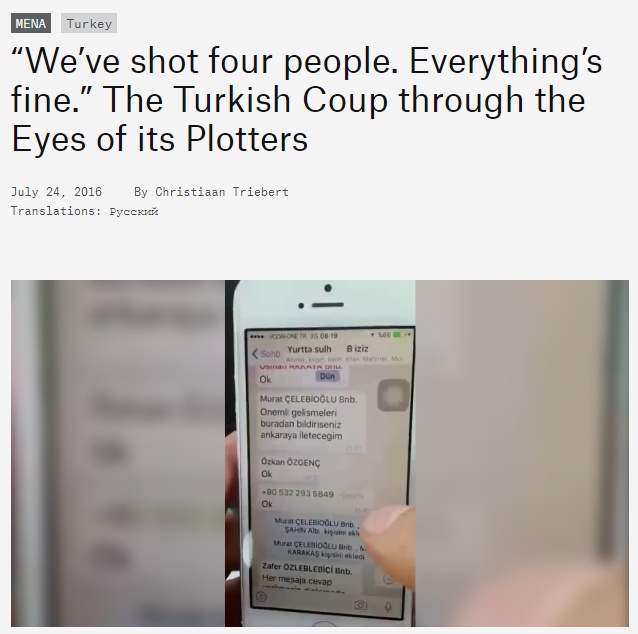
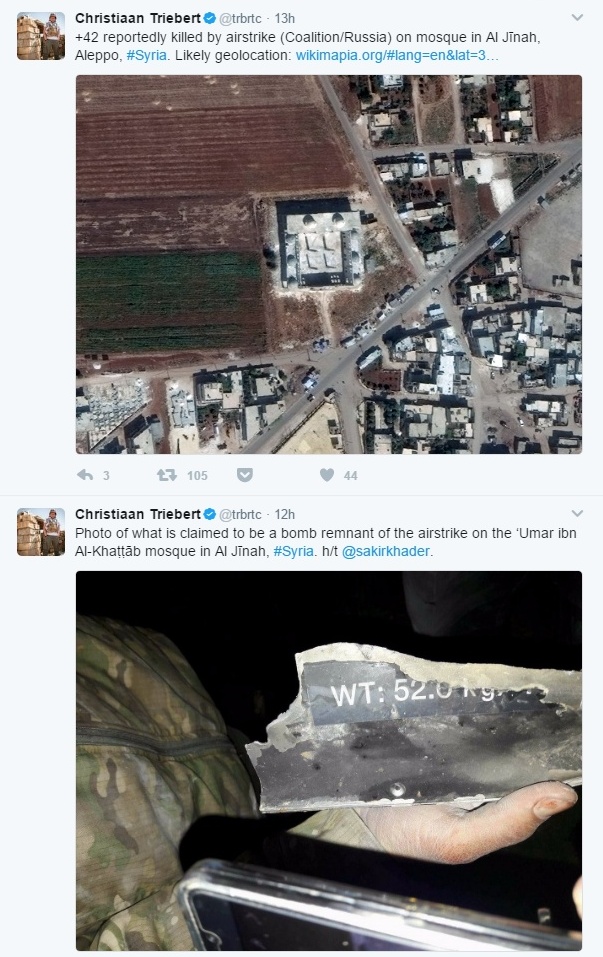
Ruben Verborgh windt zich ook nog wel op over andere dingen dan dat waarvoor hij 28 maart als spreker naar Amsterdam komt. Zo was er veel belangstelling toen hij eind vorige maand in zijn thuishaven Gent fel van leer trok tegen de Amerikaanse ideeën dat net-neutrality op internet beter afgeschaft kon worden. Dit verscheen toen over en van hem op Twitter: Velen vonden het jammer dat Christiaan Triebert op 9 maart maar 40 minuten had om voorbeelden te laten zien hoe bij Bellingcat combinaties van open bronnen op internet worden gebruikt voor allerlei analyses. Of dat ze zelfs die 40 minuten gemist hadden, omdat ze op dat moment een workshop volgden.
Velen vonden het jammer dat Christiaan Triebert op 9 maart maar 40 minuten had om voorbeelden te laten zien hoe bij Bellingcat combinaties van open bronnen op internet worden gebruikt voor allerlei analyses. Of dat ze zelfs die 40 minuten gemist hadden, omdat ze op dat moment een workshop volgden.