[Bewerking van de VOGIN-IP-nieuwsbrief van 12 februari 2025.]
Voor je het weet is het 27 maart en lopen vakgenoten de OBA binnen voor de 13e VOGIN-IP-lezing, een dag vol lezingen en een heel scala aan workshops.
Over die workshops gesproken: een aantal deelnemers moet hun keuze voor een workshop nog opgeven (tenzij ze al hebben aangegeven alleen naar lezingen-tracks te willen). Kiezen kan via de [mijn vogin] link.
Early Bird tarief nog tot en met 15 februari
 Verder willen we je er graag op attenderen dat 15 februari het Early Bird tarief afloopt. Het zou zonde zijn als je die €40 korting misloopt. Ben jij er ook bij?
Verder willen we je er graag op attenderen dat 15 februari het Early Bird tarief afloopt. Het zou zonde zijn als je die €40 korting misloopt. Ben jij er ook bij?
Link voor inschrijven: https://vogin.nl/aanbod/
Voor het complete programma: https://vogin-ip-lezing.net/programma-2025/.
Twee spraakmakende keynotes

José van Dijck opent de dag met haar inspirerende keynote: “Een publieke digitale infrastructuur voor Europa en Nederland”. Rens van de Schoot sluit de dag af met “Mensen, machines en de zoektocht naar het laatste relevante paper”. Perfect om, tijdens en na een gezellige borrel, over verder te praten en na te denken!
Innovatie ‘as we speak’
Soms haalt de werkelijkheid de programmering in. Wanneer maak je mee dat je – waar je bijzit – innovatie rechtstreeks kunt observeren? Een paar voorbeelden:
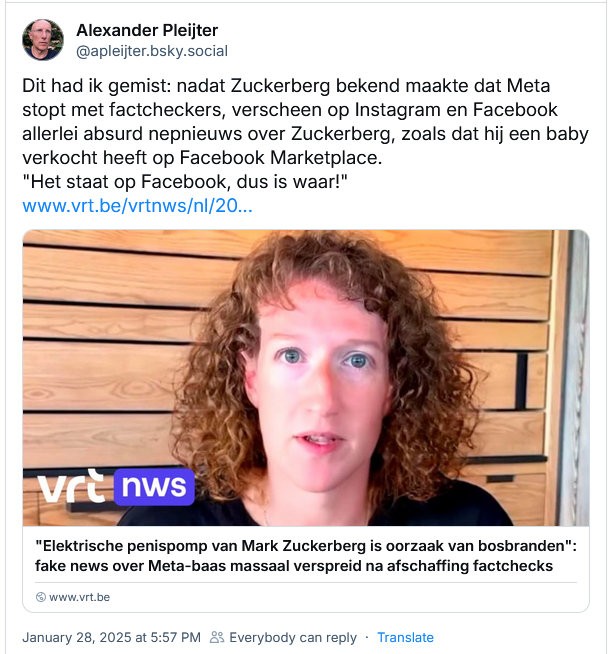
 DeepSeek is verrassend vanwege de impact en de technologie. Het is onverwachte innovatie uit een onverwachte hoek en tegen onverwacht lage kosten als we de berichten althans mogen geloven.
DeepSeek is verrassend vanwege de impact en de technologie. Het is onverwachte innovatie uit een onverwachte hoek en tegen onverwacht lage kosten als we de berichten althans mogen geloven.
Volgens Perplexity https://www.perplexity.ai/ zijn de werkelijke kosten achter DeepSeek echter aanzienlijk hoger dan de oorspronkelijk geclaimde 6 miljoen dollar voor de ontwikkeling van het model. Hoe dan ook, de ontwikkelingen maken complexe data-analyse toegankelijker voor een breder publiek, hetgeen de manier waarop men informatie zoekt en gebruikt fundamenteel verandert.
 OpenAI, het bedrijf achter ChatGPT, lanceerde afgelopen zondag “Deep Research” — een uitbreiding van zijn groeiende platform van AI-tools, die het bedrijf beschrijft als een assistent die onafhankelijk werk voor je kan doen … op het niveau van een onderzoeksanalist.”
OpenAI, het bedrijf achter ChatGPT, lanceerde afgelopen zondag “Deep Research” — een uitbreiding van zijn groeiende platform van AI-tools, die het bedrijf beschrijft als een assistent die onafhankelijk werk voor je kan doen … op het niveau van een onderzoeksanalist.”
 Hoe dat in zijn werk gaat, wordt aardig beschreven in dit uitgewerkte praktijkvoorbeeld van Andrew Maynard. Ook de interactie tussen Maynard en het systeem wordt daarin uitgebreid weergegeven.
Hoe dat in zijn werk gaat, wordt aardig beschreven in dit uitgewerkte praktijkvoorbeeld van Andrew Maynard. Ook de interactie tussen Maynard en het systeem wordt daarin uitgebreid weergegeven.
Internet, PC, smartphones en AI
Deze innovaties zijn voorbeelden van hoe onverwachte technologische doorbraken enorme impact kunnen hebben op de maatschappij en op de manier waarop we leven en werken. Als we achterom kijken, zien we sinds de jaren 90 – ja, van de vorige eeuw – verschillende technische innovaties in de geschiedenis die vergelijkbare verrassingen teweegbrachten: internet, de PC, smartphones en recent AI.
Signal
Dan is er de opmars van Signal. Honderden miljoenen mensen gebruiken intussen Signal, het privacyvriendelijke alternatief voor WhatsApp. Signal’s Meredith Walker wil dat big tech fundamenteel anders kan: Signal verkoopt je data niet, heeft geen aandeelhouders, geen winstmotief en geen tech bro als CEO. ‘We willen dat Signal óók werkt voor je moeder die technologie spannend vindt.’ Link: https://signal.org/download/
VOGIN-IP
 Het VOGIN-IP team probeert de ontwikkelingen bij te houden en hoopt dat 27 maart te laten zien met een breed scala aan lezingen en diepgravende workshops, scherp op de meest actuele ontwikkelingen om ons heen. Gezien de razendsnelle toeloop van aanmeldingen leeft dat enorm in onze beroepsgroep. Jullie zoektocht naar informatie en vakkennis willen we in de 13de editie van ons congres dan ook graag en van harte ondersteunen.
Het VOGIN-IP team probeert de ontwikkelingen bij te houden en hoopt dat 27 maart te laten zien met een breed scala aan lezingen en diepgravende workshops, scherp op de meest actuele ontwikkelingen om ons heen. Gezien de razendsnelle toeloop van aanmeldingen leeft dat enorm in onze beroepsgroep. Jullie zoektocht naar informatie en vakkennis willen we in de 13de editie van ons congres dan ook graag en van harte ondersteunen.
[Bewerking van de VOGIN-IP-nieuwsbrief van 12 februari 2025.]







 Tijdens de dag
Tijdens de dag Zelf aan de slag
Zelf aan de slag

